Blog
Afin de ne pas perdre des articles sur MADEC en général, et de pouvoir les stocker quelque part, ils sont écrits en français et en Markdown, sauvegardés sur GitHub.
Nous avons choisi un générateur de site statique nommé Hexo.
J’ai transcrit le poster soumis (et accepté?) à VSST.
J’ai aussi commencé un article sur le minimum à savoir pour configurer un ezVIS.
J’en profite pour noter les sujets (et les liens) à présenter lors de cette sprint review numéro 9 qui expose les tâches menées à bien depuis la semaine 9 de 2015.
machine virtuelle
Nous avons eu quelques soucis de requêtes répondant bizarrement sur la machine virtuelle hébergeant ezmaster et ezVIS. Nous avons d’abord cru qu’il s’agissait d’un problème de mémoire (tant le swap était peu utilisé).
La mémoire vive de la machine a donc été portée de 2Gio à 8Gio.
ezmaster
L’application castor-admin, qui sert à administrer des instances d’applications (ou apps) basées sur castor-core (comme le sont ezvis et idefix) a été renommée en ezmaster, que ce soit sur GitHub ou sur npm.
board.inist.fr
Nous avons configuré ezmaster sur la machine virtuelle pour que le nom de domaine board.inist.fr et ses sous-domaines puissent servir à publier une instance d’ezvis.
Ainsi, les instances mises en place pour la démonstration du projet au directeur de la DIST jeudi dernier (le 26/03/2015) sont accessibles de l’extérieur.
- ezPAARSE results for ST2I portal logs (march 2015): http://couperin_ezpaarseezvis640v3_3.board.inist.fr
- ISTEX - Food Science & Technology: http://dist_istexfoodscitechnezvis640v1_1.board.inist.fr
- Lorraine (Moselle) - 2007-2012: http://inist_lorraineezvis640v1_1.board.inist.fr
Les deux premières instances sont aussi disponibles dans le dépôt vitrine: showcase.
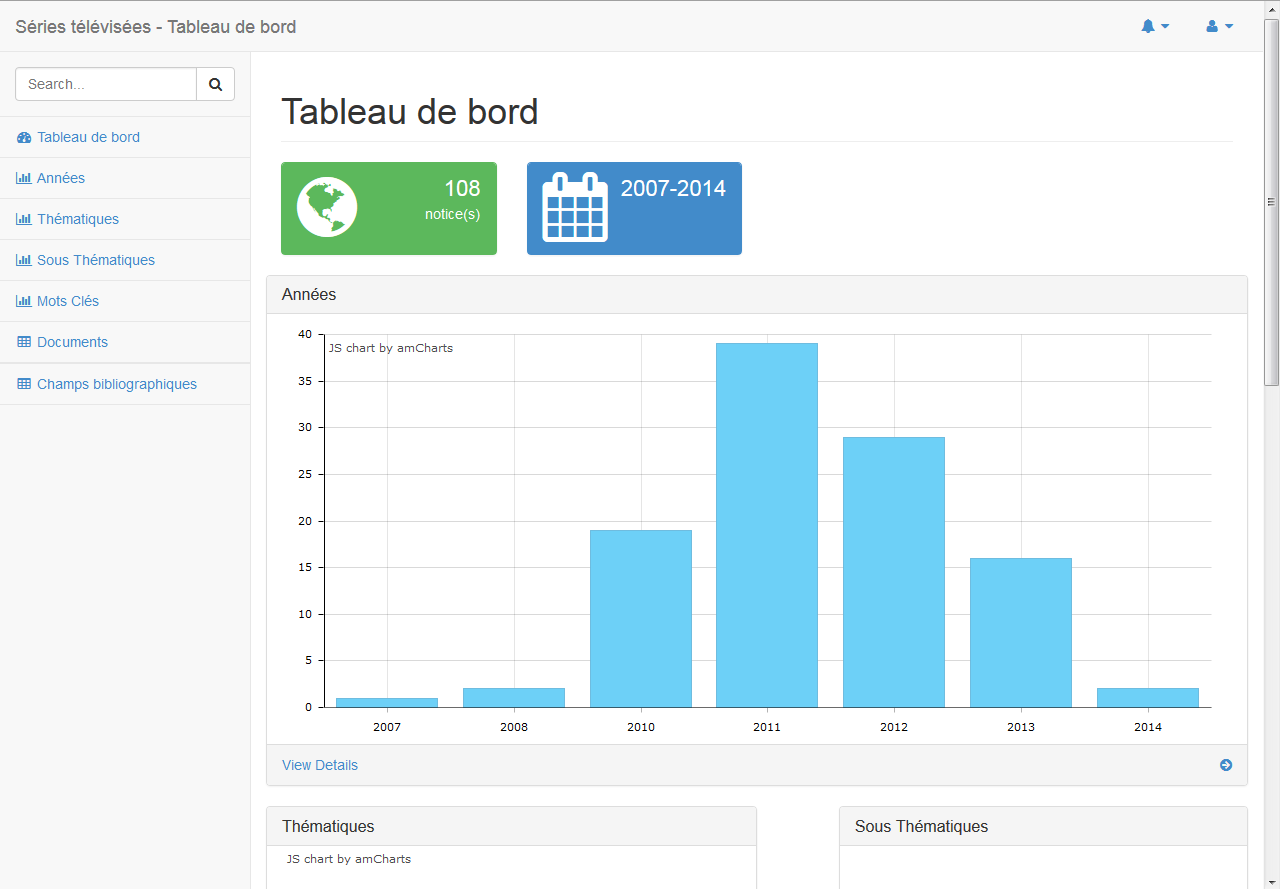
Isabelle y a aussi ajouté une étude sur les séries télévisées.
dalekjs
J’ai commencé à mettre en place des tests, non pas unitaires, mais de comportement de l’application: en utilisant dalekjs, on peut écrire des scénarios de test de l’application.
Lancement du serveur à tester:1
2$ cd ~/dev/castorjs/ezvis
$ node cli test/dataset/test2
Lancement des tests:1
2$ cd ~/dev/castorjs/ezvis
$ dalek test/test2.js
Résultat espéré:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23Running tests
Running Browser: PhantomJS
OS: linux unknown 64bit
Browser Version: 1.9.8
RUNNING TEST - "Has data"
▶ OPEN http://localhost:20002/documents.html
▶ WAITFOR Interrupted by timeout
✔ EXISTS "Showing 1 to 4 of 4 entries"
✔ TEXT "Showing 1 to 4 of 4 entries"
✔ TEXT "1906" in first line
✔ TEXT "Kurt Gödel" in first line
▶ CLICK #dataTables-documents tr:nth-child(4) td:first:first-child a
✔ TITLE Correct
✔ 5 Assertions run
✔ TEST - "Has data" SUCCEEDED
RUNNING TEST - "Good display"
▶ OPEN http://localhost:20002/display/Z5OAoW.html
✔ TITLE Correct
✔ NUMBEROFELEMENTS 3 fields displayed
✔ TEXT Name is "Douglas Hofstadter"
✔ 3 Assertions run
✔ TEST - "Good display" SUCCEEDED
8/8 assertions passed. Elapsed Time: 10.11 sec
JBJ
- on a évité d’écrire une action
mapArrayinutile (jbj#5) - j’ai ajouté l’action
substring(jbj#6), plus simple et intuitive que l’utilisation successive detruncateetshift.
ezVIS
J’ai commencé à me servir des fonctionnalités de GitHub qui ne sont pas forcément incluses dans git: le système d’issues et de milestones.
J’ai donc placé un jalon pour ce sprint, en lui donnant une date. C’est la milestone “Sprint #15W09: stabilization” d’ezvis:
- changer le label “Search” en “Filter” dans le page
/documents.html#3 - enlever le lien vers les champs depuis le tableau de bord #4
- affecter une couleur à chaque champ d’un réseau inter-champs #5
- corriger le bug d’export CSV vide de
/documents.html#6 - ajouter un seuil en-deça duquel on rassemble les valeurs dans le camembert #7
- corriger les réseaux où les arcs sont dirigés #8
- donner la possibilité de modifier la largeur de la colonne de gauche dans
/display.html#9 - restaurer la configuration des légendes #10
- donner la possibilité d’afficher aussi les années vides dans les histogrammes #11
- donner la possibilité d’afficher des labels plus courts sur les barres horizontales #12
- verbaliser les codes des pays sélectionnés dans les cartes, afin de rendre les filtres plus lisibles #13
- faire commencer l’axe des ordonnées à zéro dans les histogrammes #14
- déterminer si on peut utiliser des chaînes de caractères sur l’axe des X pour créer des diagrammes à bulles #15
- restaurer la configuration des couleurs #16