Voici le support de la Sprint Review n°11, concernant les exports.
Tâches
- 19 tâches prévues
- 16 tâches effectuées (dont 11 avaient été prévues)
- 24 tâches au total
- plus de 38 points de complexité prévus
- 38 points de complexité effectués (un peu plus que la moyenne)
VSST 2015
ezVIS a été présenté à VSST 2015 par Anne-Marie BADOLATO, le 13 mai 2015.
À l’occasion, une instance protégée par login/mot de passe a été présentée, qui concernait une étude réelle pour l’IRSTV. Cette instance tournait sur la machine virtuelle d’intégration, car nous n’avons pas été en mesure de mettre en place la machine de production et de la tester dans les temps.
forever
En effet, une des différences entre la machine de production et la machine d’intégration est que la machine de production utilise forever pour s’assurer qu’ezmaster est relancé automatiquement si jamais il plante.
Ce qui a retardé l’utilisation de la machine de production est qu’ezmaster s’est révélé incapable, quand il était lancé par forever, de créer des fichiers temporaires dans le répertoire courant. Ceci a donné lieu à une correction d’ezmaster, mais pas assez tôt pour que ce soit la machine de production qu’on utilise.
ezMaster
En plus de la correction apportée pour fonctionner avec forever, ezMaster a connu plusieurs changements:
- une optimisation de la fonction reverse-proxy, ce qui a éliminé les ralentissements observés après quelques utilisations des instances qu’
ezmastersurveillait 11fba01, - l’affichage de l’app utilisée par une instance, et de sa version #30
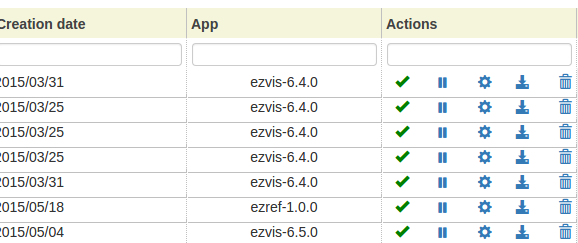
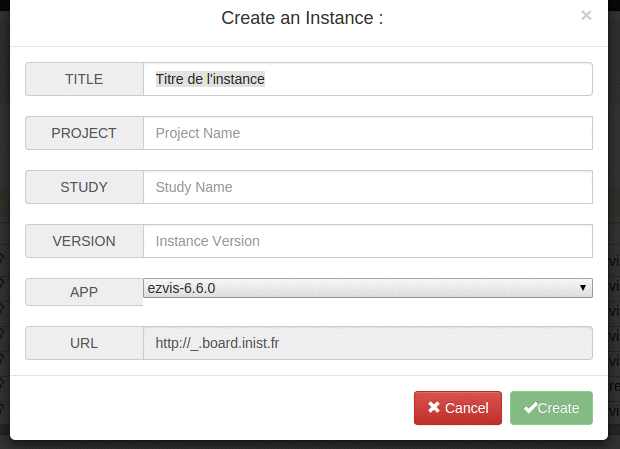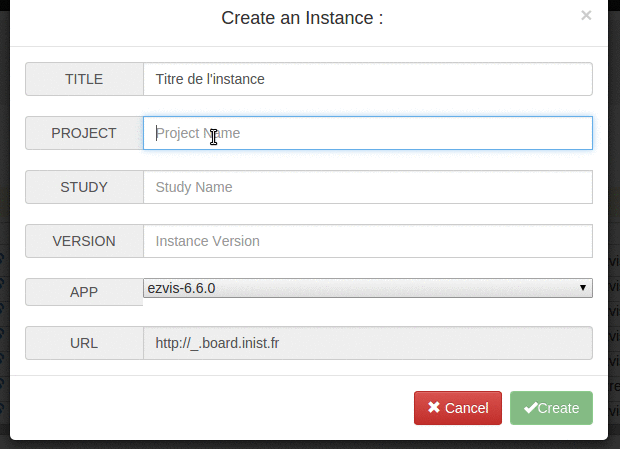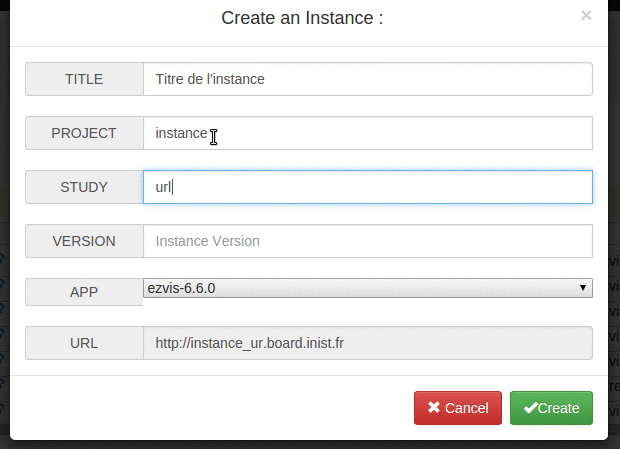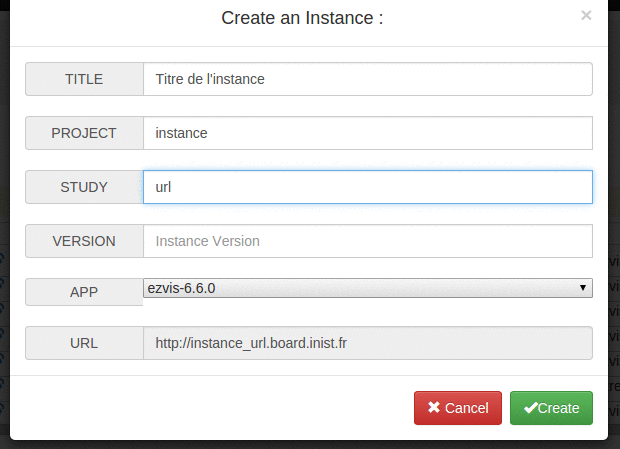
- ajout d’une prévisualisation de l’URL que va donner le nom technique d’une instance qu’on est en train de créer #32
- le numéro de version d’une instance a été rendu optionnel (dans le but de simplifier les URL résultantes) #18
ezVIS
La plupart des tâches de ce sprint étaient liées à ezvis.
Bug
Nous avons corrigé un bug qui se produisait dans un réseau avec des facettes: quand on cliquait sur une facette, les restrictions apportées pour la création du réseau (en particulier selector, mais aussi maxItems et threshold) n’étaient pas appliquées.
Cela posait un problème quand le nombre de liens du réseau non restreint était trop important pour que le réseau puisse s’afficher dans le navigateur, gelant ainsi le navigateur.
Toutefois, cette correction ne touche que selector car les autres restrictions, appliquées en plus de celle de la facette, mène souvent à des graphes vides, ce qui est difficilement compréhensible.
Voir issue #39.
Améliorations mineures
- #38: ajout de la possibilité de rendre les labels sur les graphiques plus courts (sur le même principe que ce qui avait déjà été fait pour les
horizontalbars), pour leshistograms, et pour lespies. Pour ce dernier, ce ne sont pas les labels eux-mêmes qui sont raccourcis, mais leur équivalent dans la légende du camembert,
- #31: la référence à amCharts qui apparaissait comme un petit lien
js Chartsen haut à gauche des graphiques a été déplacé en bas à droite des graphiques, emplacement jugé moins gênant (il est moins souvent placé sur une barre sur laquelle on clique). Rappel: cette référence est nécessaire, car l’enlever requerrait de payer la société qui produit cette bibliothèque, - #28: les labels des camemberts (qui apparaissent autour des parts du graphique) sont maintenant désactivables (pour ne plus voir que les nombres). Il faut utiliser
removeLabels: true, - #37: nous avons ajouté un exemple de configuration
ezvispour des fichiers.tsvdans le showcase.
Chargement de .TSV
Après l’écriture de la mini-configuration de déclaration du loader pour charger des .tsv minimaux, nous avons voulu créer un exemple réel de chargement de fichiers tirés du WoS (Web of Science).
Il s’est trouvé que les fichiers tels quels ne se chargeaient pas dans ezvis, même après avoir utilisé des options peu courantes de castor-load-csv.
Après investigation, le nœud du problème se trouvait dans la bibliothèque csv-string qui analyse le TSV dans castor-load-csv. L’auteur de la bibliothèque l’a améliorée pour qu’elle prenne aussi en compte ces fichiers TSV (il n’y a pas vraiment de norme concernant la manière d’encoder les doubles quotes (guillemets anglais) dans ces fichiers). Voir les tests proposés pour plus de détails.
Exports
Le thème de ce sprint était l’export en général. Il se spécialise en:
- export des images des graphiques
- export des documents associés aux graphiques
- export des données des graphiques (ce n’était pas demandé)
graphiques
amCharts
Les graphiques horizontalbars, histogram, pie et map utilisent la même bibliothèque qui vient d’être mise à jour. Surprise: le thème de cette mise à jour est l’export. Cette version améliore une fonctionnalité qui existait déjà, en l’étendant à d’autres formats et aussi aux données qui ont permis la création du graphique.
Ces graphiques simples sont donc désormais exportables à partir d’un menu présent en haut à droite. Ils permettent:
- l’annotation (dessin sur l’image, à la souris),
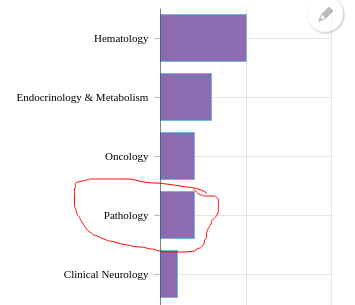
- la sauvegarde de l’image (avec son éventuelle annotation), aux formats JPG, PNG, SVG et même PDF,
- la sauvegarde des données ayant permis la construction du graphique (sauf pour les cartes, que nous n’avons pas réussi à activer), aux formats CSV, XLSX et JSON.
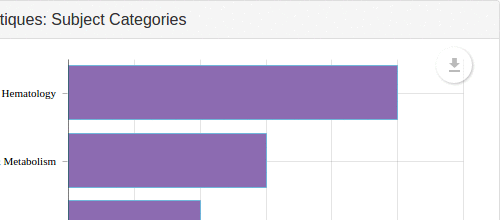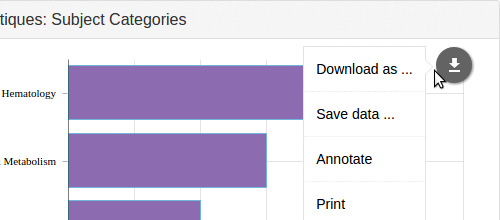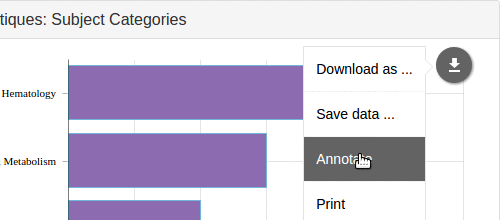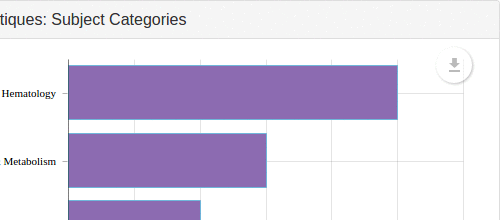
Lors des tests, nous nous sommes aperçus que l’export CSV exportait toutes les valeurs sauf la première (en général la plus grande). La déclaration d’un problème dans leur système de support a provoqué une mise à jour dans la journée. Bravo à amCharts.
cytoscape
Nous avions reperé qu’il existait aussi une fonction d’export dans la bibliothèque Cytoscape que nous utilisons pour la représentation graphique des réseaux. Il s’est avéré que cette fonction était beaucoup moins clé-en-main que celle d’amCharts.
Le menu d’export des réseaux se résume donc à un bouton qui exporte une image PNG.
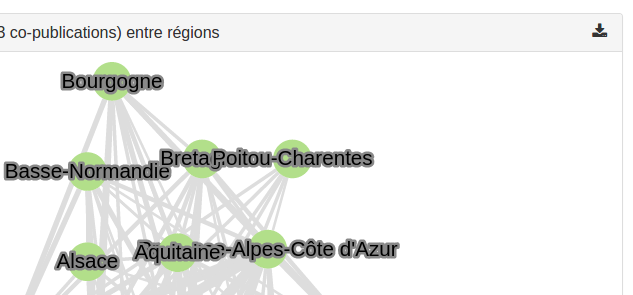
Pour le détails des exports des graphiques, voir le ticket #36.
documents
L’export des documents était déjà présent dans ezvis, mais uniquement sur la page des documents, où on exporte tous les documents présents sur la page, avec une sélection basique, par filtrage.
Il est désormais présent aussi sur la page des graphiques, et prend aussi en compte les filtres venant du graphique et des facettes. Voir #20.
http dans les documentFields / nosave
Lors de la dernière Sprint Review, nous avions montré un usage des flyingFields qui était certes visuel, mais qui s’est avéré non pertinent: nous modifiions à la volée (flying) les identifiants du graphique.
Ce faisant, nous avions rendu les filtres inopérants (cliquer sur un pays ne retournait plus les documents publiés dans ces pays).
Cela n’invalide pas l’utilité des flyingFields, puisque leur utilisation reste valable quand on modifie les valeurs projetées dans les graphiques (par exemple, pour afficher un taux de citation par année, et pas seulement un nombre de citations).
Mais le besoin d’externaliser des tables de références (ici, une correspondance entre les noms de pays et leur code ISO) perdure, donc nous avons implémenté l’utilisation de sources extérieures (comme dans les corpusFields) depuis les documentFields.
Comme nous ne voulons pas surcharger la base en dupliquant des tables dans chaque document, nous avons introduit une propriété pour ces documentFields que nous voulons utiliser, mais pas sauvegarder dans la base: nosave. Il suffit de positionner cette propriété à true pour que le champ ne soit pas sauvegardé mais tout de même disponible pour le calcul d’autres documentFields.
JBJ
zip
Pour calculer des expressions impliquant les valeurs de deux tableaux (comme pour normaliser des valeurs par années), il nous fallait être capable de fusionner deux tableaux de même longueur.
Exemple:
1 | { |
En divisant citationsPerYear[i] par publiPerYear[i]:
1 | { |
Dans cet exemple, "zip": [ "citationsPerYear", "publiPerYear" ] renvoie, en JBJ:
1 | [ |
Voir JBJ#8
getproperty
De plus, il manquait une action capable de retourner la valeur d’un tableau associatif correspondant à une clé:
Ex:
1 | { |
renvoie
1 | "a" |
et
1 | { |
renvoie
1 | 1 |
Voir JBJ#9
commande ezref
La version 1.0.0 d’ezref devait être lancée de manière non triviale quand ce n’était pas par ezmaster. Nous avons donc publié la version 1.1.0 qui ajoute une commande ezref quand on l’installe via:
1 | $ npm install -g ezref |
Installation / mise à jour
Après l’écriture de tests via dalekjs, l’installation d’ezvis ramenait des modules utiles uniquement pour le développement (pour ces tests).
Pour éviter de grossir les fichiers d’ezvis, on peut l’installer en utilisant l’option --production:
1 | $ npm install --production -g ezvis |
C’est la même commande qui permet de mettre à jour ezvis en installant la dernière version à la place de l’éventuelle version installée, quelle qu’elle soit.
À ce jour, c’est la version 6.6.0.