Ce quatorzième et avant-dernier sprint avait pour thème la gestion des erreurs. Nous avons apporté quelques modifications concernant la gestion des erreurs et leur signalement, ajouté une visualisation du chargement des données à ezvis et quelques moyens de valider ce chargement. Pendant la chasse au bug que comporte tout sprint, nous avons écrit une commande permettant de mieux situer d’où viennent certaines erreurs: csv-string. Au passage, nous avons ajouté des fonctionnalités à JBJ (dans l’optique de faciliter l’utilisation de ressources externes).
Tâches
9 tâches prévues
6 tâches terminées
plus de 21,5 points de complexité prévus
32 points de complexité effectués
Comme la dernière fois, nous étions en présence d’un bug, par essence d’estimation difficile tant qu’on n’a pas entamé son analyse.
Gestion des erreurs
Les erreurs de chargement sont maintenant sauvegardées dans un fichier instance_errors.log (où instance est le nom de l’instance, c’est-à-dire le nom du répertoire où se trouvent les données).
Lorsque la variable d’environnement NODE_ENV ne vaut pas production, ces erreurs sont aussi affichées dans la sortie standard d’erreur. En clair, cela signifie que si on utilise ezvis via un terminal on peut voir ces erreurs (sauf si la variable en question a été créée/modifiée), mais que pour l’instant, l’utilisation exclusive d’ezmaster ne le permet pas.
Lors du chargement des données (par exemple au démarrage d’ezvis), au lieu de laisser l’administrateur d’une instance dans l’expectative, à ne pas savoir où en est le chargement, on affiche maintenant la progression du chargement en direct:
Jusqu’à présent, les erreurs de JBJ (le langage utilisé pour la configuration d’ezvis) étaient traitées de manière hétérogène. Dorénavant, elles sont toutes traitées de la même manière, et affichées lors du chargement. On ajoute, derrière le message d’erreur qui peut encore être abscons (c’est un message d’erreur javascript), le nom de l’action qui a provoqué cette erreur (mais pas le nom de ses alias).
Lors de la mise au point d’une instance, on peut rencontrer une erreur JBJ concernant une action parseCSV ou parseCVSFile. Sachant que ces actions JBJ utilisent une bibliothèque appelée csv-string, il est pratique de pouvoir reproduire (puis éliminer) ces erreurs en dehors du processus ezvis (qui peut être long, si le nombre de documents est élevé). C’est pourquoi j’ai écrit une commande csv-string qui applique l’analyse d’un CSV avec les options par défaut en utilisant la même bibliothèque qu’ezvis: csv-string.
Son installation est similaire à celle d’ezvis:
1
$ npm install -g csv-string-command
Cette commande lit l’entrée standard et écrit sur la sortie standard (et éventuellement la sortie standard d’erreur).
Chargement de ressources externes en CSV
Lors d’un test d’utilisation de ressources externes, nous nous sommes rendus compte qu’il était bien plus facile d’accéder à des ressources au format JSON, qu’à des ressources au format CSV.
l’action parseCSV est faite pour analyser une chaîne de caractère représentant un champ (une colonne), et non un fichier CSV complet. Elle renvoie uniquement la première ligne d’un fichier CSV.
l’action parseCSVFile que nous avons ajoutée pallie le problème précédent, mais ne permet pas d’obtenir un objet directement utilisable (équivalent à un tableau associatif), mais un tableau de tableaux:
nous avons donc crée une nouvelle action, arrays2objects, qui permet de modifier ce tableau (transformer les tableaux internes en objets) qui pourront ensuite être utilisés par l’action array2object pré-existante (que l’on utilisait déjà avec le fichier JSON externe).
Ce sprint n°13 a été consacré à la consolidation de l’outil ezVIS. Nous avons principalement modifié la documentation et corrigé des bugs.
Tâches
20 tâches prévues
18 tâches effectuées (dont 15 avaient été prévues)
24 tâches au total
plus de 24 points de complexité prévus
37,5 points de complexité effectués
Le nombre de points de complexité prévus était très peu précis, car nous avions plusieurs bugs. Les bugs sont par définition difficile à estimer. N’ont pas été comptabilisés ici les travaux de déclaration des bugs par les documentalistes/utilisateurs.
Production
Basculements des URL publics
Les URL publics des rapports du service Appui au Pilotage de l’Inist pointent maintenant sur la machine de production dont la mise au point a été finalisée (via puppet). Au passage, les instances ont été copiées de la machine d’intégration vers la machine de production (et vérifiées par les gestionnaires de ces instances).
Augmentation de l’espace disque
À cause de la manière dont ezVIS gère le cache des requêtes qu’il utilise, la place utilisée par une de ses instances dans la base de données augmente à mesure que ses utilisateurs en font des usages variés.
C’est pourquoi nous avons fait augmenter par le service Ingénierie de Production l’espace disque disponible sur la machine de production (c’était 10 Go au total sur la machine d’intégration, c’est 200 Go sur la machine de production).
Bugs
Déclaration des bugs par les gestionnaires
Ce sprint ayant été dédié à la consolidation d’ezVIS, nous avons demandé aux gestionnaires des instances déjà existantes de faire une déclaration formelle des bugs qu’ils ont rencontré. De plus, ils ont dû faire en faire qu’on puisse reproduire ces bugs. Nous avons donc utilisé l’application ezREF présente sur la machine d’intégration, et fait utiliser l’interface de dépôt de fichiers sur ce serveur pour y mettre:
la description du dysfonctionnement (dans un fichier *README.txt)
la configuration de l’instance (dans un fichier *.json)
le(s) corpus dans un ou plusieurs fichier(s) dont préfixe était commun à tous les fichiers concernant ce bug.
Tout le monde a parfaitement joué le jeu et nous avons obtenu la description de 5 bugs:
Dans plusieurs des bugs déclarés, lors du chargement des données au premier lancement, ezVIS ne rendait pas la main: la déclaration Files and Database are synchronised. n’arrivait pas (même quand tous les documents avaient été chargés), et donc encore moins le calcul des corpusFields (les métriques sur le corpus). Souvent d’ailleurs, on pouvait contourner ce problème en relançant simplement l’instance (ezVIS détectait alors que le(s) fichier(s) n’avaient pas changés, et passait directement à l’étape suivante: le calcul des métriques).
Il s’est avéré que ce cas arrivait quand une erreur survenait lors du chargement (soit un problème de parsing du fichier, soit un problème JBJ lors du calcul des documentFields). L’analyse a révélé que lors du chargement, les erreurs étaient complètement ignorées, et qu’ezVIS essayait quand même de traiter les données, sans même afficher l’erreur.
Dorénavant, l’erreur est affichée, accompagnée du nom du fichier et du numéro du document, dans ce fichier, pour lequel l’erreur s’est produite.
$ ezvis bibliotep_entier_pertes Core version : 2.5.0 Configuration : /home/parmentf/dev/castorjs/bugs/bibliotep_entier_pertes.json Theme : /home/parmentf/dev/castorjs/ezvis App : ezvis 6.7.3 Source : /home/parmentf/dev/castorjs/bugs/bibliotep_entier_pertes Server is listening on port 3000: http://localhost:3000 Index field : annee/annee_1 Index field : titre/titre_1 Index field : wid/wid_1 Index field : neoplasms/neoplasms_1 Index field : techniques/techniques_1 Index field : pays/pays_1 Index field : auteurs/auteurs_1 Index field : vpmid/vpmid_1 Index field : elements/elements_1 Index field : pmid/pmid_1 Index field : anatomical/anatomical_1 Index field : isotopes/isotopes_1 Index field : source/source_1 Index field : text/text_text error [TypeError: Cannot call method 'slice' of undefined] in file /home/parmentf/dev/castorjs/bugs/bibliotep_entier_pertes/bibliotep_entier_pertes_2014-2015.csv document # 3431 error [TypeError: Cannot call method 'slice' of undefined] in file /home/parmentf/dev/castorjs/bugs/bibliotep_entier_pertes/bibliotep_entier_pertes_2014-2015.csv document # 3643 error [TypeError: Cannot call method 'slice' of undefined] in file /home/parmentf/dev/castorjs/bugs/bibliotep_entier_pertes/bibliotep_entier_pertes_2014-2015.csv document # 3645 error [TypeError: Cannot call method 'slice' of undefined] in file /home/parmentf/dev/castorjs/bugs/bibliotep_entier_pertes/bibliotep_entier_pertes_2014-2015.csv document # 3738 error [TypeError: Cannot call method 'slice' of undefined] in file /home/parmentf/dev/castorjs/bugs/bibliotep_entier_pertes/bibliotep_entier_pertes_2014-2015.csv document # 3855 error [TypeError: Cannot call method 'slice' of undefined] in file /home/parmentf/dev/castorjs/bugs/bibliotep_entier_pertes/bibliotep_entier_pertes_2014-2015.csv document # 3895 Files and Database are synchronised. 127.0.0.1 - - [20/Jul/2015:15:41:03 +0000] "GET /compute.json?operator=count&field=wid HTTP/1.1"200 - "-""-" 127.0.0.1 - - [20/Jul/2015:15:41:03 +0000] "GET /compute.json?operator=distinct&field=annee HTTP/1.1"200 - "-""-" 127.0.0.1 - - [20/Jul/2015:15:41:03 +0000] "GET /compute.json?operator=distinct&field=isotopes HTTP/1.1"200 - "-""-" Corpus fields computed.
Cette correction a modifier le comportement d’ezVIS sur plusieurs des bugs déclarés, révélant alors que c’était plutôt les fichiers d’origine qui ne respectaient pas le format demandé (CVS et l’échappement des guillemets, par exemple).
Correction: mettre à jour l’instance quand la configuration est modifiée
Un comportement pratique d’ezVIS a cessé de fonctionner il y a déjà quelques sprints: quand on modifie la configuration d’une instance et qu’on la relance sans modifier les données, les documents ne prennent pas en compte les modifications de la configuration. En particulier, quand un gestionnaire modifie les documentFields, ces nouveaux champs ne sont calculés que pour les nouveaux documents (ou pour aucun). C’est très handicapant quand on met au point une configuration car on est alors contraint, quand on passe par ezMaster, de supprimer l’instance et de la recréer (ce qui implique de recharger les données).
Ce comportement a été rétabli: quand on modifie une configuration, si les documents sont plus anciens que le fichier de configuration, ezVIS les mets à jour en prenant en compte la nouvelle configuration.
Correction: mettre à jour l’instance quand les fichiers sont modifiés
Quand un fichier déjà chargé dans l’instance est remplacé par un fichier du même nom mais contenant des lignes en moins, les lignes ne disparaissaient pas.
Après une enquête approfondie (merci à Yannick pour son aide), nous avons trouvé et corrigé le bug.
ATTENTION : il est possible que des métriques faisant un comptage des documents ne soient pas mises à jour immédiatement. Dans ce cas, il est nécessaire de redémarrer l’instance (ou de la mettre en pause de la relancer, via ezMaster) pour bénéficier d’un calcul à jour.
Nouvelle documentation
Il commençait à être difficile de s’y retrouver dans l’ancienne documentation d’ezVIS, qui tenait sur une page, mais était dépourvue de table des matières (et souvent faisait référence à la documentation d’autres projets).
Il a donc été décidé d’utiliser un système dédié à la documentation de projets informatiques, qui se base sur le même format que l’ancienne documentation (Markdown): ReadTheDocs.
La nouvelle documentation, divisée en pages plus courtes, et agrémentée d’illustrations, est donc disponible sur http://ezvis.readthedocs.org/ ou http://ezvis.rtfd.org/. Elle est mise à jour à chaque mise à jour du dépôt GitHub, et responsive (lisible sur un téléphone mobile). Au besoin, on pourrait même en garder des versions différentes (une pour la version 6.*, et une pour la version suivante, par exemple).
Quand on a oublié MongoDB avant de lancer ezVIS, il y a maintenant un message d’erreur:
1
failed to connect to [localhost:27017]
Il est certes sibyllin, mais il est difficile de faire mieux (principalement en raison du fait qu’ezVIS n’établit la connexion à MongoDB que lorsqu’il en a besoin).
oubli du paramètre
ezVIS a un paramètre obligatoire: le chemin du répertoire où se trouvent les fichiers contenant les données. Auparavant, le message était très technique, et même les programmeurs avaient besoin de toute leur expérience pour le comprendre.
Maintenant c’est celui ci:
1 2 3 4 5
$ ezvis Usage: ezvis data data being a directory path, and data.json the settings file. See https://github.com/madec-project/ezvis for more details.
Afin de pouvoir afficher les erreurs JBJ (dues à la configuration des documentFields, corpusFields et flyingFields), nous avons mené une opération d’homogénéisation du traitement des erreurs dans JBJ. Il sont maintenant traités comme n’importe quelle erreur dans ezVIS (en particulier lors du chargement des données).
Quand getProperty et getPropertyVar sont appliqués à un tableau, il est plus naturel d’utiliser getIndex et getIndexVar (cliquez sur les liens pour voir des exemples dans la documentation de JBJ version ReadTheDocs).
Les exemples étaient initialement classés par sujet, et partageaient leur input. Nous avons supprimé le premier niveau (sujet). Nous en avons aussi profité pour supprimer un effet de bord gênant: quand une feuille de style modifiait l’input, elle le modifiait aussi pour les autres exemples du même sujet. Chaque exemple est maintenant indépendant.
Pour en profiter: npm install -g castor-clean. (version 1.2.0).
ezref: usage
Comme pour ezVIS, quand on oublie le paramètre obligatoire d’ezref, on a maintenant un message indiquant l’usage normal de la commande:
1 2 3 4 5
$ ezref Usage: ezref public public being a directory path, and public.json the settings file. See https://github.com/madec-project/ezref for more details.
ezvis: mise à jour de dépendances
Il existe un site qui recense la fraîcheur des dépendences de projets Node, et qui signale des trous de sécurité potentiels.
J’ai donc procédé à quelques mises à jour (marked, sha1, et qs).
Sans doute à surveiller de près.
Comme d’habitude, pour profiter des ajouts de ce sprint dans ezVIS :
Nous voici arrivés à la sprint review n°12, qui concerne les calculs complexes. Comme le dit Anne-Marie, la division est une opération complexe par rapport au simple comptage. Mais la complexité dont nous parlons réside plutôt dans l’appel des données intégrées aux calculs: ils sont externes, dans des tableaux.
Tâches
10 tâches prévues
10 tâches effectuées (dont 9 avaient été prévues)
24 tâches au total
plus de 25 points de complexité prévus
24,5 points de complexité effectués
Ce ne sont là que les points pour le développement, sachant que les utilisateurs ont fait plus (notamment sur les tests).
Calcul d’un taux de citation normalisé
Nous avons identifié 4 étapes pour le calcul d’un taux de citation normalisé:
calculer le nombre de publications par année
calculer le nombre de citations par année
calculer le taux de citations par année
normaliser ce taux par rapport à un taux de citation global
1. Calculer le nombre de publications par année
Ce calcul se fait sur le corpus complet, donc on peut stocker le résultat dans un corpusFields (appelons-le publiPerYear). Nous avons un opérateur classique pour compter le nombre de documents par valeurs distinctes d’un champ: distinct.
Calculer le taux de citations par année revient à diviser la valeur de citationsPerYear par celle qui correspond dans publiPerYear (donc, le nombre de citations pour une année par le nombre de publications pour cette année, ce qui donne bien le nombre moyen de citations par publication, ou taux de citation):
Cet objet JSON donne directement accès à un taux de citation global, en utilisant, par exemple "getproperty": "2008", on récupère la valeur associée: 15.56.
C’est pourquoi nous avons créé l’action array2object, qui transforme un tableau d’objets {_id,value} en objet associant les _id et les values.
Malheureusement, l’action JBJ getproperty ne prend qu’un paramètre littéral, et s’applique sur l’environnement courant. Or, nous voulons parcourir le tableau des taux de citations pour pouvoir normaliser chaque valeur par rapport à la valeur correspondante dans le tableau global.
Nous avons donc créé le pendant de getproperty prenant des variables en paramètres: getpropertyvar, qui prend en paramètre un tableau de deux noms de variables: la variable contenant le tableau, et la variable contenant l’indice à aller chercher.
Ça a permis d’appliquer le flyingFields suivant au résultat de l’opérateur retournant le nombre de publication par année:
Rappel :flyingFields a accès à la fois aux corpusFields et aux variables _id et value retournées par l’opérateur (distinct dans ce cas), citationsPerYear et globalCitationRatios étant des corpusFields, ils sont accessibles aussi.
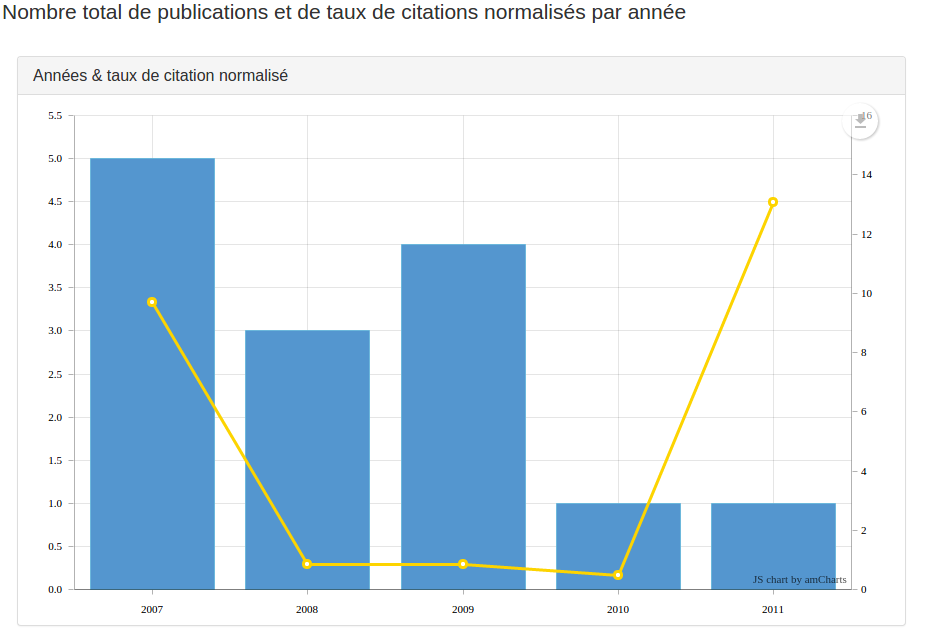
Un taux de citation normalisé par année est intéressant à comparer à un nombre de publications par année, sur un corpus donné. Dans les versions 6.6 d’ezVIS, le seul moyen disponible était de créer un graphe avec les publications par année, puis un autre graphe avec les taux de citations pour qu’ils soient un au-dessus de l’autre dans le tableau de bord. Pas très pratique.
Nous avons donc introduit le moyen de le faire avec ezVIS 6.7.2, en ajoutant la propriété overlay à un graphique de type histogram:
1 2 3 4 5 6 7 8 9 10
{ "fields": ["content.json.Py"], "type": "histogram", "title": "Années & taux de citations normalisés", "help": "Nombre total de publications et de taux de citations normalisés par année", "overlay": { "label": "Taux de citation normalisé par année:", "flying": [ "normalizeCitationRatioPerYear" ] } }
Un overlay doit contenir un label (qui s’affiche sur les points de la ligne), et un flying qui s’appliquera sur les data fournis par l’opérateur (par défaut distinct) et les fields.
La convention est un qu’un overlay se nourrit d’éléments semblables à ceux d’un chart normal (composé d’un _id et d’une value) auquels on ajoute une deuxième valeur value2. Il faut donc modifier le flyingFields nommé normalizeCitationRatioPerYear exposé plus haut:
Quand on veut appliquer le même genre de flyingFields à des valeurs déjà présentes dans corpusFields, on est quand même obligé de passer par une route de type compute qui applique un opérateur retournant systématiquement un tableau de résultats (même quand il n’y en a qu’un). Or le principe des flyingFields est de s’appliquer à tous les éléments de ce tableau data. On obtient donc un tableau de tableaux, qu’ezVIS n’est pas capable d’interpréter. Nous avons donc ajouté la propriété firstOnly qui, au lieu de renvoyer un tableau d’éléments, ne renvoie que le premier élément du tableau. Voir le ticket Add a “firstOnly” parameter to the routes returning data.
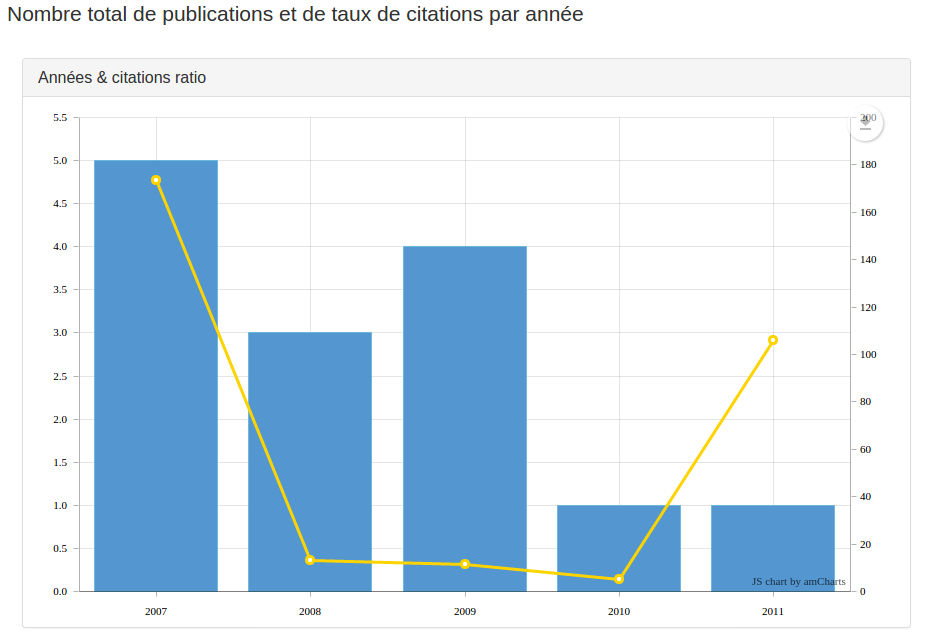
Ainsi, quand on veut afficher un histogram avec un overlay contenant les taux de citations par années (présents dans le corpusFields appelé citationsPerYear), il faut utiliser une configuration comme celle-là (contenant un firstOnly):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
{ "dashboard": { "charts": [ { "fields": ["content.json.Py"], "type": "histogram", "title": "Années & taux de citation", "help": "Nombre total de publications et de taux de citations par année", "overlay": { "label": "Taux de citation par année:", "firstOnly": true, "flying": [ "publiCitationRatioPerYear" ] } } ] } }
sans oublier de modifier le flyingFields nommé publiCitationRatioPerYear pour qu’il renvoie deux valeurs:
Nous utilisons des fichiers extraits du WoS (Web of Science) au format TSV (Tabulation Separated Values), et certaines notices passaient mal.
Nous avons trouvé des champs contenant des guillemets (double quotes anglaises), non échappés (mais c’est normal, il n’y avait pas d’ambiguité), et c’est visiblement ce qui posait problème. Une correction a été apportée à la bibliothèque qui analyse les CSV: csv-string. Voir ticket 19 de csv-string.
Mais après tests, les fichiers qui posaient problème ne passent toujours pas correctement: sur un corpus de 999 notices, seules les notices contenant des guillemets ne sont pas chargées (en enlevant les guillemets, tout passe).
Tests de dépôt de plusieurs fichiers (XML ou CSV)
Nous avons remarqué un comportement erronné d’ezVIS: quand on met deux fichiers XML dans le répertoire des données, on obtient des erreurs SAX, alors que séparément, les deux fichiers sont bien chargés.
Après test, ce comportement ne se produit pas avec des fichiers CSV.
Test de la machine de production avec plus de dix rapports
13 rapports ont été créés sur la machine de production, sans aucun problème (rappel: 12 rapports étaient déjà de trop sur la machine d’intégration avant qu’ezMaster soit corrigé).
Test de la prise en compte des modifications de configuration dans ezMaster
Les modifications des documentFields dans la configuration d’une instance ne sont pas prises en compte, même après rechargement du corpus.
Test de la prise en compte des modifications de corpus dans ezMaster
Les modifications du corpus d’une instance (suppression de notices) ne sont pas prises en compte. Par contre l’ajout d’un nouveau corpus dans la même instance est bien traité et les modifications des documentFields dans la configuration d’une instance sont également prises en compte pour le nouveau corpus.
Documentation du protocole HTTP dans les documentFields
L’utilisation du protocole HTTP dans les documentFields n’avait pas été documentée, c’est chose faite: 6a7147.
Modification des entêtes des exports
Les exports de documents prennent maintenant comme noms de colonnes les labels des champs, et non plus leurs identifiants. Voir ticket 48.
Mise à jour de getting-started-with-visir
Le dépôt getting-started-with-visir a été renommé en getting-started-with-ezvis, la documentation adaptée à la version 6+ d’ezVIS, ainsi que l’exemple fourni.
Explication d’ezVIS pour ISTEX
Kibana ne fournissant pas assez de graphiques, ISTEX s’est intéressé à ezVIS. C’est l’occasion pour nous d’expérimenter le loader de corpus JSON castor-load-jsoncorpus.
Voici le support de la Sprint Review n°11, concernant les exports.
Tâches
19 tâches prévues
16 tâches effectuées (dont 11 avaient été prévues)
24 tâches au total
plus de 38 points de complexité prévus
38 points de complexité effectués (un peu plus que la moyenne)
VSST 2015
ezVIS a été présenté à VSST 2015 par Anne-Marie BADOLATO, le 13 mai 2015. À l’occasion, une instance protégée par login/mot de passe a été présentée, qui concernait une étude réelle pour l’IRSTV. Cette instance tournait sur la machine virtuelle d’intégration, car nous n’avons pas été en mesure de mettre en place la machine de production et de la tester dans les temps.
forever
En effet, une des différences entre la machine de production et la machine d’intégration est que la machine de production utilise forever pour s’assurer qu’ezmaster est relancé automatiquement si jamais il plante.
Ce qui a retardé l’utilisation de la machine de production est qu’ezmaster s’est révélé incapable, quand il était lancé par forever, de créer des fichiers temporaires dans le répertoire courant. Ceci a donné lieu à une correction d’ezmaster, mais pas assez tôt pour que ce soit la machine de production qu’on utilise.
ezMaster
En plus de la correction apportée pour fonctionner avec forever, ezMaster a connu plusieurs changements:
une optimisation de la fonction reverse-proxy, ce qui a éliminé les ralentissements observés après quelques utilisations des instances qu’ezmaster surveillait 11fba01,
l’affichage de l’app utilisée par une instance, et de sa version #30
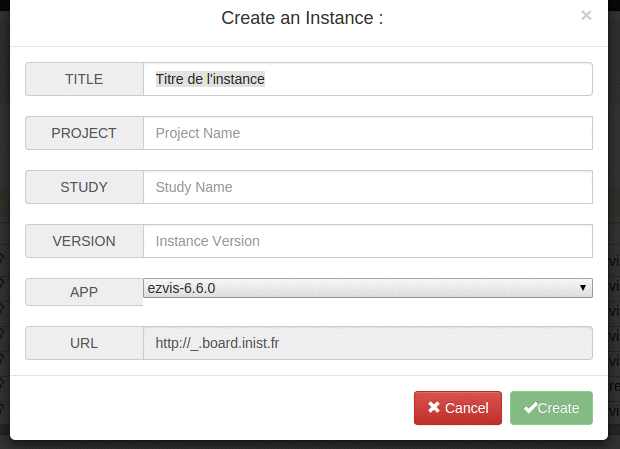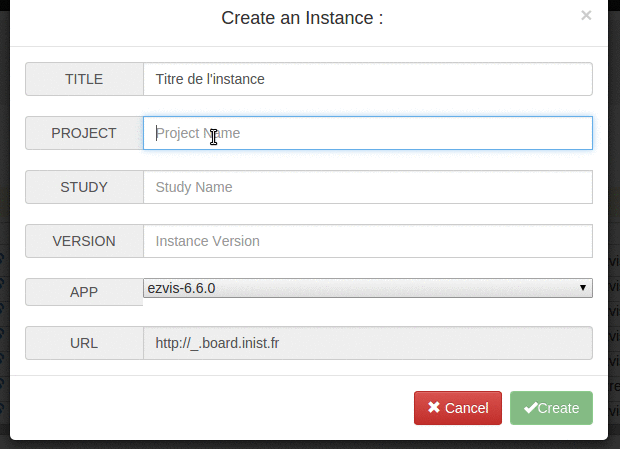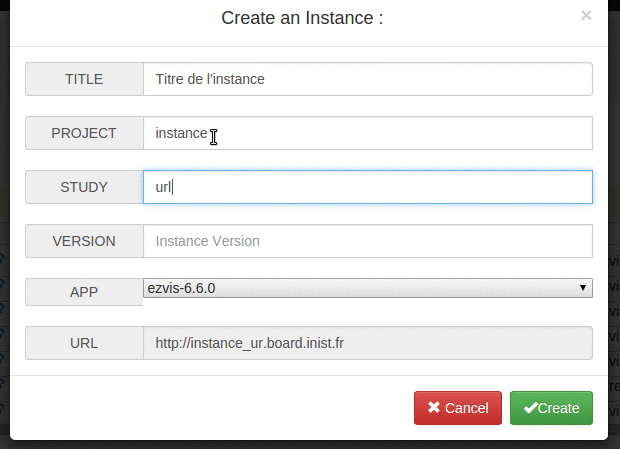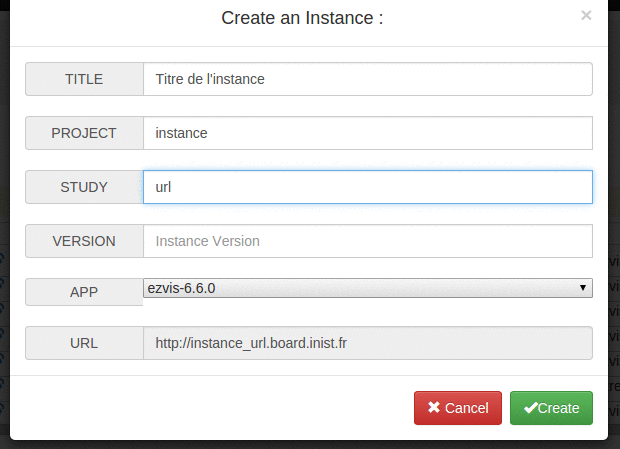
ajout d’une prévisualisation de l’URL que va donner le nom technique d’une instance qu’on est en train de créer #32
le numéro de version d’une instance a été rendu optionnel (dans le but de simplifier les URL résultantes) #18
ezVIS
La plupart des tâches de ce sprint étaient liées à ezvis.
Bug
Nous avons corrigé un bug qui se produisait dans un réseau avec des facettes: quand on cliquait sur une facette, les restrictions apportées pour la création du réseau (en particulier selector, mais aussi maxItems et threshold) n’étaient pas appliquées. Cela posait un problème quand le nombre de liens du réseau non restreint était trop important pour que le réseau puisse s’afficher dans le navigateur, gelant ainsi le navigateur.
Toutefois, cette correction ne touche que selector car les autres restrictions, appliquées en plus de celle de la facette, mène souvent à des graphes vides, ce qui est difficilement compréhensible.
#38: ajout de la possibilité de rendre les labels sur les graphiques plus courts (sur le même principe que ce qui avait déjà été fait pour les horizontalbars), pour les histograms, et pour les pies. Pour ce dernier, ce ne sont pas les labels eux-mêmes qui sont raccourcis, mais leur équivalent dans la légende du camembert,
#31: la référence à amCharts qui apparaissait comme un petit lien js Charts en haut à gauche des graphiques a été déplacé en bas à droite des graphiques, emplacement jugé moins gênant (il est moins souvent placé sur une barre sur laquelle on clique). Rappel: cette référence est nécessaire, car l’enlever requerrait de payer la société qui produit cette bibliothèque,
#28: les labels des camemberts (qui apparaissent autour des parts du graphique) sont maintenant désactivables (pour ne plus voir que les nombres). Il faut utiliser removeLabels: true,
#37: nous avons ajouté un exemple de configuration ezvis pour des fichiers .tsvdans le showcase.
Chargement de .TSV
Après l’écriture de la mini-configuration de déclaration du loader pour charger des .tsv minimaux, nous avons voulu créer un exemple réel de chargement de fichiers tirés du WoS (Web of Science). Il s’est trouvé que les fichiers tels quels ne se chargeaient pas dans ezvis, même après avoir utilisé des options peu courantes de castor-load-csv.
Après investigation, le nœud du problème se trouvait dans la bibliothèque csv-string qui analyse le TSV dans castor-load-csv. L’auteur de la bibliothèque l’a améliorée pour qu’elle prenne aussi en compte ces fichiers TSV (il n’y a pas vraiment de norme concernant la manière d’encoder les doubles quotes (guillemets anglais) dans ces fichiers). Voir les tests proposés pour plus de détails.
Exports
Le thème de ce sprint était l’export en général. Il se spécialise en:
export des images des graphiques
export des documents associés aux graphiques
export des données des graphiques (ce n’était pas demandé)
graphiques
amCharts
Les graphiques horizontalbars, histogram, pie et map utilisent la même bibliothèque qui vient d’être mise à jour. Surprise: le thème de cette mise à jour est l’export. Cette version améliore une fonctionnalité qui existait déjà, en l’étendant à d’autres formats et aussi aux données qui ont permis la création du graphique.
Ces graphiques simples sont donc désormais exportables à partir d’un menu présent en haut à droite. Ils permettent:
l’annotation (dessin sur l’image, à la souris),
la sauvegarde de l’image (avec son éventuelle annotation), aux formats JPG, PNG, SVG et même PDF,
la sauvegarde des données ayant permis la construction du graphique (sauf pour les cartes, que nous n’avons pas réussi à activer), aux formats CSV, XLSX et JSON.
Lors des tests, nous nous sommes aperçus que l’export CSV exportait toutes les valeurs sauf la première (en général la plus grande). La déclaration d’un problème dans leur système de support a provoqué une mise à jour dans la journée. Bravo à amCharts.
cytoscape
Nous avions reperé qu’il existait aussi une fonction d’export dans la bibliothèque Cytoscape que nous utilisons pour la représentation graphique des réseaux. Il s’est avéré que cette fonction était beaucoup moins clé-en-main que celle d’amCharts.
Le menu d’export des réseaux se résume donc à un bouton qui exporte une image PNG.
Pour le détails des exports des graphiques, voir le ticket #36.
documents
L’export des documents était déjà présent dans ezvis, mais uniquement sur la page des documents, où on exporte tous les documents présents sur la page, avec une sélection basique, par filtrage.
Il est désormais présent aussi sur la page des graphiques, et prend aussi en compte les filtres venant du graphique et des facettes. Voir #20.
http dans les documentFields / nosave
Lors de la dernière Sprint Review, nous avions montré un usage des flyingFields qui était certes visuel, mais qui s’est avéré non pertinent: nous modifiions à la volée (flying) les identifiants du graphique. Ce faisant, nous avions rendu les filtres inopérants (cliquer sur un pays ne retournait plus les documents publiés dans ces pays). Cela n’invalide pas l’utilité des flyingFields, puisque leur utilisation reste valable quand on modifie les valeurs projetées dans les graphiques (par exemple, pour afficher un taux de citation par année, et pas seulement un nombre de citations).
Mais le besoin d’externaliser des tables de références (ici, une correspondance entre les noms de pays et leur code ISO) perdure, donc nous avons implémenté l’utilisation de sources extérieures (comme dans les corpusFields) depuis les documentFields.
Comme nous ne voulons pas surcharger la base en dupliquant des tables dans chaque document, nous avons introduit une propriété pour ces documentFields que nous voulons utiliser, mais pas sauvegarder dans la base: nosave. Il suffit de positionner cette propriété à true pour que le champ ne soit pas sauvegardé mais tout de même disponible pour le calcul d’autres documentFields.
Pour calculer des expressions impliquant les valeurs de deux tableaux (comme pour normaliser des valeurs par années), il nous fallait être capable de fusionner deux tableaux de même longueur.
La version 1.0.0 d’ezref devait être lancée de manière non triviale quand ce n’était pas par ezmaster. Nous avons donc publié la version 1.1.0 qui ajoute une commande ezref quand on l’installe via:
1
$ npm install -g ezref
Installation / mise à jour
Après l’écriture de tests via dalekjs, l’installation d’ezvis ramenait des modules utiles uniquement pour le développement (pour ces tests).
Pour éviter de grossir les fichiers d’ezvis, on peut l’installer en utilisant l’option --production:
1
$ npm install --production -g ezvis
C’est la même commande qui permet de mettre à jour ezvis en installant la dernière version à la place de l’éventuelle version installée, quelle qu’elle soit.
Voici venue la revue de sprint numéro 10, qui a pour thème principal les ressources externes.
Tâches
18 tâches prévues
10 tâches effectuées
22 tâches au total
plus de 46 points de complexité prévus (avec des incertitudes)
36,5 points de complexité résolus (avec des tâches non prévues): dans la moyenne
madec-project.github.io
J’ai créé un page pour l’organisation madec-project sur GitHub, celle qui contient tous les programmes liés au projet MADEC. GitHub offrant l’hébergement d’un site statique, nous avions déjà opté pour Hexo pour ce blog.
Un compte Twitter ezvis_project a aussi été créé (en ces temps de communication autour d’ezVIS, ça peut servir).
vimadec / vpmadec / puppet
Le travail avec Patrice, Martial et Philippe porte ses fruits:
ajout d’un script d’installation d’une app ezmaster à partir de l’URL de son .tar.gz,
mise sous surveillance du processus ezmaster afin de le relancer automatiquement quand il s’arrête (via forever),
création d’une machine virtuelle de production vpmadec,
création d’un accélérateur sécurisé vers cette machine virtuelle.
ezVIS
Test sous node v0.12
En utilisant nvm, nous avons lancé et testé à la main ezVIS, et tout a marché.
Il a néanmoins fallu passer par un npm rebuild pour recompiler/récupérer les modules binaires correspondant à cette version (principalement bson et kerberos)
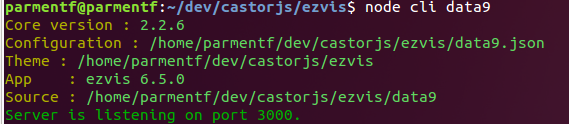
Affichage de la version
Pour faciliter les échanges avec les utilisateurs (il y en a eu avec une personne d’Orléans, par mél), on affiche la version d’ezVIS dans le navigateur:
mais aussi lors du lancement d’une instance ezVIS:
login/password
On peut maintenant limiter l’accès à un rapport ezVIS en utilisant la clé access, contenant un login et un mot de passe soit plain, soit sha1:
Le mot de passe sous forme plain est simplement le mot de passe en clair. Mais comme ce n’est pas une bonne pratique, on peut remplacer son usage par celui de sha1 qui remplace un mot de passe par son empreinte SHA-1.
Ainsi, on connaît l’empreinte du mot de passe, mais pas le mot de passe lui-même.
Pour obtenir l’empreinte SHA-1 d’un mot de passe, on peut utiliser des commandes comme shasum ou sha1sum (en n’incluant pas de passage à la ligne dans le mot de passe), ou bien des sites de génération comme SHA1 online.
Accès aux ressources externes
ezref
On peut avoir besoin de ressources externes à ezvis (parce que de simples fichiers), mais avec la possibilité de remplacer ces fichiers de référence (tables de correspondance, listes, …).
Utiliser ezref, l’application pour ezMaster qui met à disposition via le protocole http des fichiers qu’ezMaster vous permet de déposer est la solution.
Pour pouvoir stocker les ressources: ezref (serveur web statique).
flyingFields
Les flyingFields sont les cousins des documentFields et des corpusFields. Ils sont un croisement, dans le sens où ils permettent l’interopérabilité des uns et des autres.
JBJ
Pour pouvoir appliquer une table de correspondance présente dans les corpusFields, on a ajouté une action mappingVar à JBJ, qui fonctionne comme mapping, mais dont les arguments sont différents.
Exemple: externaliser la table de correspondance d’une carte géographique
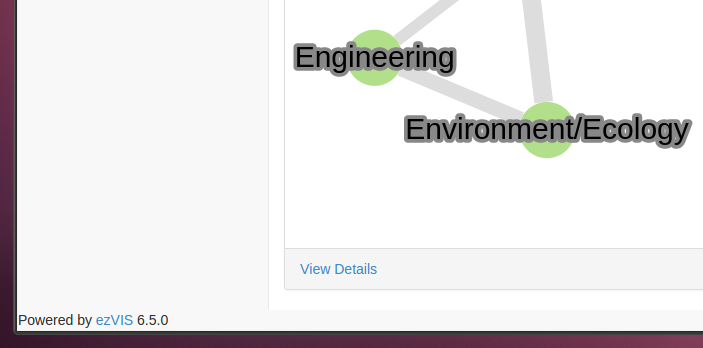
Pour projeter des données sur la carte du monde, jusqu’ici, on était obligé de traduire les noms des pays en codes ISO (c’est ainsi que sont identifiés les pays sur la carte):
Puis, nous avons créé un opérateur similaire à mapping qui, au lieu de prendre en entrée l’objet courant et en paramètre la table de correspondance, permet de mettre en paramètre deux noms de variable: l’entrée et la table. Il s’appelle mappingVar (ou combine).
Donc, grâce à ezref, on peut mettre la table de correspondance sur un serveur externe, et le charger dans un corpusFields, accessible comme une variable dans les flyingFields:
Afin de ne pas perdre des articles sur MADEC en général, et de pouvoir les stocker quelque part, ils sont écrits en français et en Markdown, sauvegardés sur GitHub.
Nous avons choisi un générateur de site statique nommé Hexo.
J’ai aussi commencé un article sur le minimum à savoir pour configurer un ezVIS.
J’en profite pour noter les sujets (et les liens) à présenter lors de cette sprint review numéro 9 qui expose les tâches menées à bien depuis la semaine 9 de 2015.
machine virtuelle
Nous avons eu quelques soucis de requêtes répondant bizarrement sur la machine virtuelle hébergeant ezmaster et ezVIS. Nous avons d’abord cru qu’il s’agissait d’un problème de mémoire (tant le swap était peu utilisé).
La mémoire vive de la machine a donc été portée de 2Gio à 8Gio.
ezmaster
L’application castor-admin, qui sert à administrer des instances d’applications (ou apps) basées sur castor-core (comme le sont ezvis et idefix) a été renommée en ezmaster, que ce soit sur GitHub ou sur npm.
board.inist.fr
Nous avons configuré ezmaster sur la machine virtuelle pour que le nom de domaine board.inist.fr et ses sous-domaines puissent servir à publier une instance d’ezvis.
Ainsi, les instances mises en place pour la démonstration du projet au directeur de la DIST jeudi dernier (le 26/03/2015) sont accessibles de l’extérieur.
Les deux premières instances sont aussi disponibles dans le dépôt vitrine: showcase.
Isabelle y a aussi ajouté une étude sur les séries télévisées.
dalekjs
J’ai commencé à mettre en place des tests, non pas unitaires, mais de comportement de l’application: en utilisant dalekjs, on peut écrire des scénarios de test de l’application.
Lancement du serveur à tester:
1 2
$ cd ~/dev/castorjs/ezvis $ node cli test/dataset/test2
Running tests Running Browser: PhantomJS OS: linux unknown 64bit Browser Version: 1.9.8 RUNNING TEST - "Has data" ▶ OPEN http://localhost:20002/documents.html ▶ WAITFOR Interrupted by timeout ✔ EXISTS "Showing 1 to 4 of 4 entries" ✔ TEXT "Showing 1 to 4 of 4 entries" ✔ TEXT "1906"in first line ✔ TEXT "Kurt Gödel"in first line ▶ CLICK #dataTables-documents tr:nth-child(4) td:first:first-child a ✔ TITLE Correct ✔ 5 Assertions run ✔ TEST - "Has data" SUCCEEDED RUNNING TEST - "Good display" ▶ OPEN http://localhost:20002/display/Z5OAoW.html ✔ TITLE Correct ✔ NUMBEROFELEMENTS 3 fields displayed ✔ TEXT Name is "Douglas Hofstadter" ✔ 3 Assertions run ✔ TEST - "Good display" SUCCEEDED 8/8 assertions passed. Elapsed Time: 10.11 sec
JBJ
on a évité d’écrire une action mapArray inutile (jbj#5)
j’ai ajouté l’action substring (jbj#6), plus simple et intuitive que l’utilisation successive de truncate et shift.
ezVIS
J’ai commencé à me servir des fonctionnalités de GitHub qui ne sont pas forcément incluses dans git: le système d’issues et de milestones.