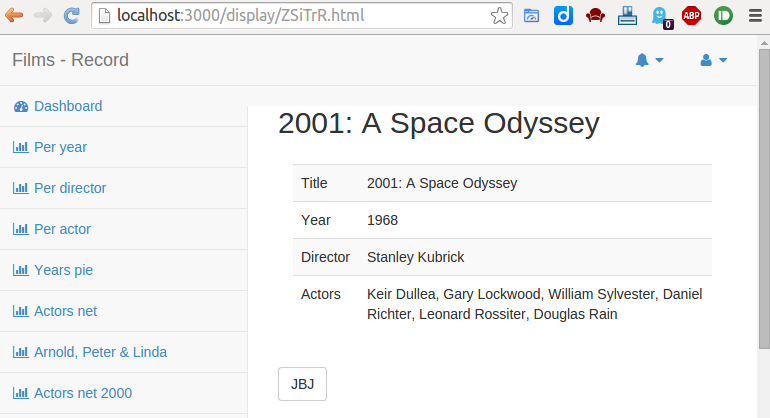
Pour ce quinzième et dernier sprint, nous devions terminer, polir, affiner, régler, en un mot peaufiner l’application ezVIS.
Tâches
19 tâches prévues
17 tâches terminées
plus de 43 points de complexité prévus
30 points de complexité effectués
D’une manière générale, nous nous sommes concentrés sur la stabilité de l’application, et donc sur la réduction de la dette technique.
Nous avons aussi rencontré des problèmes sur ezMaster, qui ne pouvaient apparaître qu’après suffisamment d’utilisation, et résolu un bug dont la présence était aléatoire.
Dette technique
La dette technique est la distance à parcourir, en termes de développement, pour parvenir au programme le plus cohérent et le plus à facile maintenir.
Les actions suivantes ont réduit cette dette.
Correction de connexionURI en connectionURI
Le programme et ses options étant intégralement en anglais, il nous semblait incohérent de laisser une option avec une orthographe française: connexionURI.
Le cœur d’ezVIS est un module nommé castor-core dont nous savons qu’il va évoluer (notamment les URL utilisés par ezVIS). Les routes (ou URL) fournies par castor-core version 2 seront encore disponibles dans sa version 3, mais préfixées par /-/v2. Nous avons donc changé tous les appels à ces URL dans ezVIS.
Pour éviter des surprises lors des futures installations d’ezVIS, au cas où un des modules dont il dépend ne respecterait pas le semantic versioning, nous avons pensé qu’il serait utile de figer les numéros de version de ces dépendances.
Il existe justement une commande du gestionnaire de modules de node qui le permet: npm shrinkwrap. Malheureusement, celle-ci ne distingue pas encore les modules optionnels des modules obligatoires, et il se trouve qu’un module optionnel n’est pas utile ailleurs que sur Mac, mais que de plus il ne s’y installe pas, cassant ainsi l’installation d’ezvis dès qu’on utilise shrinkwrap (le rendant ainsi obligatoire). La feuille de route de npm laisse à penser que d’ici un an, ce problème n’existera plus. D’ici là, nous compterons sur la gestion sémantique de version des modules. S’ils la pratiquaient tous, moins de problèmes seraient à craindre.
Plusieurs icones étaient présentes dans l’entête d’ezVIS: celle des alertes (qui avertissait quand une synchronisation avait eu lieu, mais nous nous sommes aperçus que personne ne s’en servait), et celle de l’utilisateur (qui n’a jamais été fonctionnelle).
Jusqu’à présent, le graphe superposé avait une couleur fixe : le jaune.
Si cette couleur convient la plupart du temps, nous avons souhaité donner le choix au gestionnaire en ajoutant l’option color à la partie overlay de la configuration :
Corriger l’authentification derrière un reverse proxy
ezVIS peut être configuré pour n’autoriser l’accès qu’à un utilisateur particulier. Dans notre établissement, les instances d’ezVIS sont derrière un reverse proxy (ou proxy inverse) dont le comportement n’a pas été cohérent: l’adresse IP du visiteur était soit l’adresse de ce proxy (comportement attendu), soit une adresse locale (127.0.0.1), autorisant alors l’accès à l’instance. Nous avons donc corrigé ezVIS pour qu’il tienne compte de l’entête HTTP x-forwarded-for qui, elle, contient bien l’adresse IP du visiteur (pas celle du proxy).
Nous voulions pouvoir installer automatiquement, via le logiciel SCCM, ezVIS sur plusieurs postes Windows à la fois, dans les services de notre établissement. Malheureusement, SCCM prenant l’identité de l’administrateur de la machine pour installer, il n’a pas de répertoire utilisateur. Ce répertoire utilisateur étant indispensable à l’installeur Windows de node pour fonctionner, nous avons dû renoncer à ce projet.
Malgré tout, l’installation manuelle de node est très simple, nous avons donc opté pour un compromis en automatisant uniquement l’installation de MongoDB, ce qui simplifie tout de même la procédure d’installation à l’INIST.
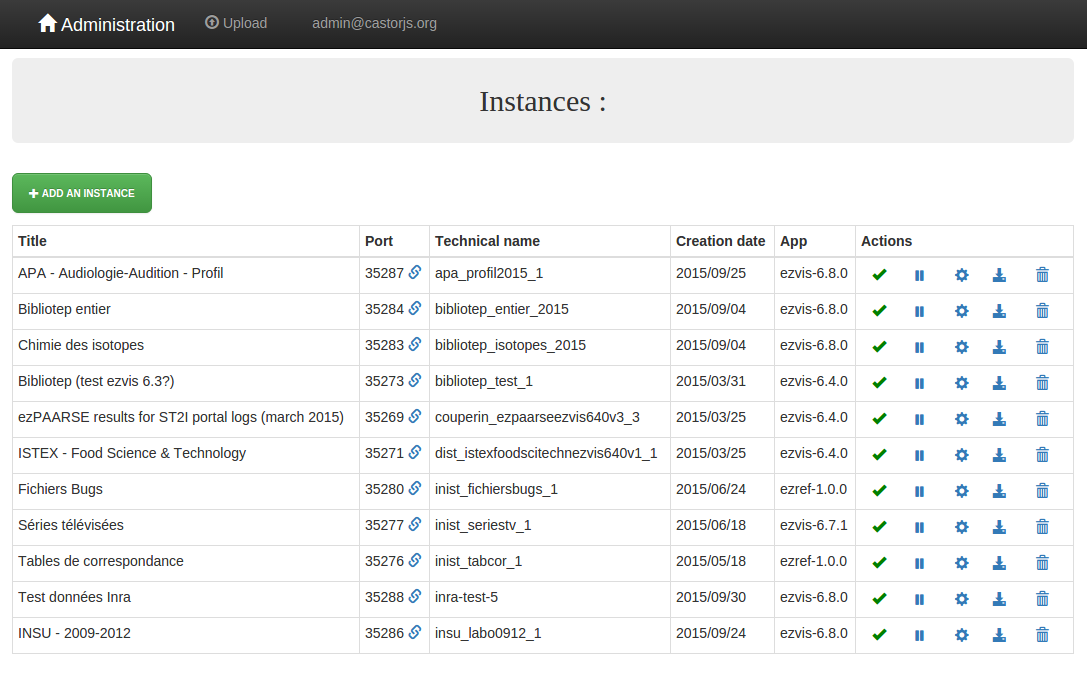
ezMaster
Remplacement de SlickGrid par un tableau HTML
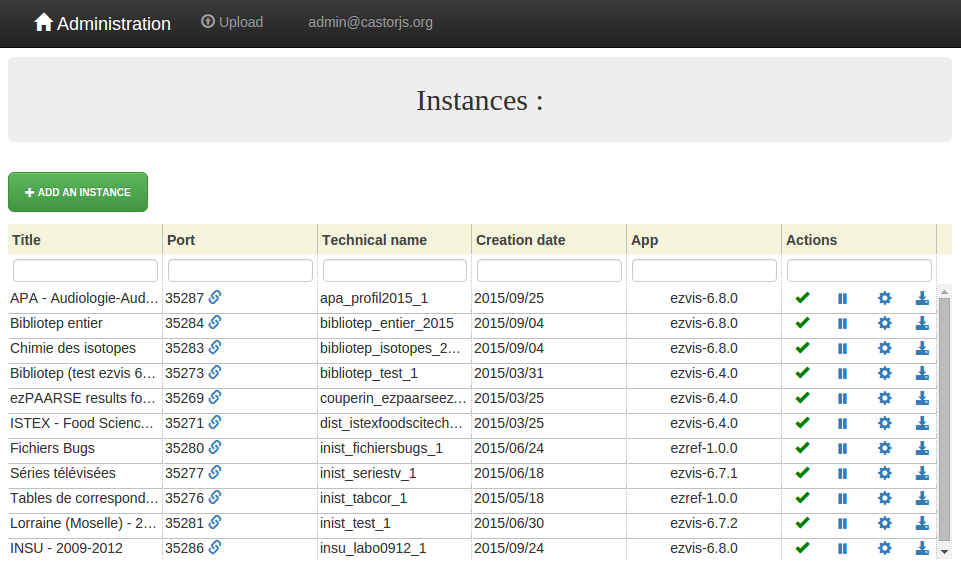
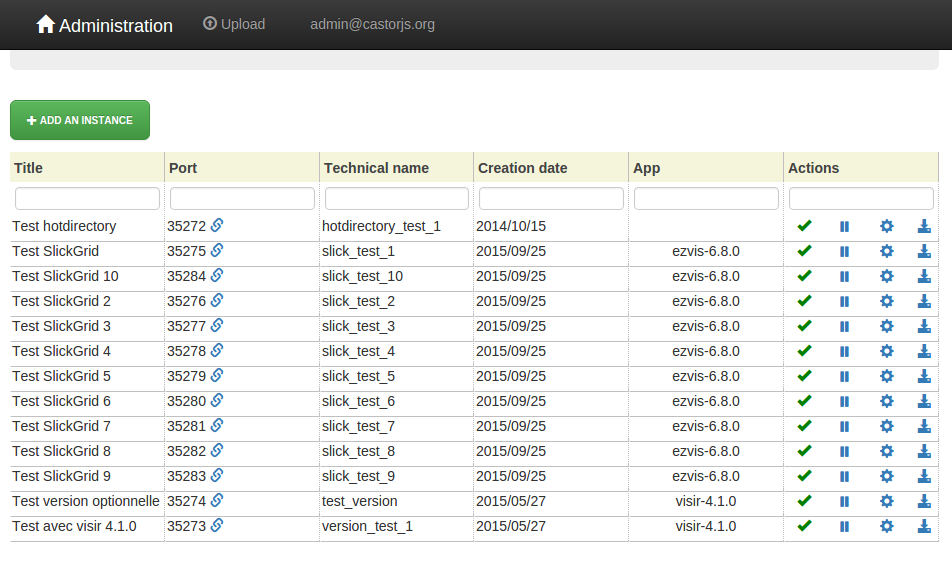
En dépassant 13 instances dans ezMaster, nous avons rencontré une limite: l’ascenseur disparait au-delà de 13 instances, empêchant toute action sur les dernières (configuration, ajout de données, suppression, …) :
La technologie utilisée, SlickGrid, est complexe et inutile pour le nombre d’instances que nous gérons: nous l’avons remplacée par un simple tableau HTML sans pagination, ni filtre, ni tri.
Jusqu’à présent, le nom technique d’une instance est composé du nom du projet, de l’étude, et optionnellement d’une version, le tout séparé par des soulignés. Dorénavant, et pour mieux satisfaire les normes sur les URL, ces séparateurs seront des tirets.
Ce quatorzième et avant-dernier sprint avait pour thème la gestion des erreurs. Nous avons apporté quelques modifications concernant la gestion des erreurs et leur signalement, ajouté une visualisation du chargement des données à ezvis et quelques moyens de valider ce chargement. Pendant la chasse au bug que comporte tout sprint, nous avons écrit une commande permettant de mieux situer d’où viennent certaines erreurs: csv-string. Au passage, nous avons ajouté des fonctionnalités à JBJ (dans l’optique de faciliter l’utilisation de ressources externes).
Tâches
9 tâches prévues
6 tâches terminées
plus de 21,5 points de complexité prévus
32 points de complexité effectués
Comme la dernière fois, nous étions en présence d’un bug, par essence d’estimation difficile tant qu’on n’a pas entamé son analyse.
Gestion des erreurs
Les erreurs de chargement sont maintenant sauvegardées dans un fichier instance_errors.log (où instance est le nom de l’instance, c’est-à-dire le nom du répertoire où se trouvent les données).
Lorsque la variable d’environnement NODE_ENV ne vaut pas production, ces erreurs sont aussi affichées dans la sortie standard d’erreur. En clair, cela signifie que si on utilise ezvis via un terminal on peut voir ces erreurs (sauf si la variable en question a été créée/modifiée), mais que pour l’instant, l’utilisation exclusive d’ezmaster ne le permet pas.
Lors du chargement des données (par exemple au démarrage d’ezvis), au lieu de laisser l’administrateur d’une instance dans l’expectative, à ne pas savoir où en est le chargement, on affiche maintenant la progression du chargement en direct:
Jusqu’à présent, les erreurs de JBJ (le langage utilisé pour la configuration d’ezvis) étaient traitées de manière hétérogène. Dorénavant, elles sont toutes traitées de la même manière, et affichées lors du chargement. On ajoute, derrière le message d’erreur qui peut encore être abscons (c’est un message d’erreur javascript), le nom de l’action qui a provoqué cette erreur (mais pas le nom de ses alias).
Lors de la mise au point d’une instance, on peut rencontrer une erreur JBJ concernant une action parseCSV ou parseCVSFile. Sachant que ces actions JBJ utilisent une bibliothèque appelée csv-string, il est pratique de pouvoir reproduire (puis éliminer) ces erreurs en dehors du processus ezvis (qui peut être long, si le nombre de documents est élevé). C’est pourquoi j’ai écrit une commande csv-string qui applique l’analyse d’un CSV avec les options par défaut en utilisant la même bibliothèque qu’ezvis: csv-string.
Son installation est similaire à celle d’ezvis:
1
$ npm install -g csv-string-command
Cette commande lit l’entrée standard et écrit sur la sortie standard (et éventuellement la sortie standard d’erreur).
Chargement de ressources externes en CSV
Lors d’un test d’utilisation de ressources externes, nous nous sommes rendus compte qu’il était bien plus facile d’accéder à des ressources au format JSON, qu’à des ressources au format CSV.
l’action parseCSV est faite pour analyser une chaîne de caractère représentant un champ (une colonne), et non un fichier CSV complet. Elle renvoie uniquement la première ligne d’un fichier CSV.
l’action parseCSVFile que nous avons ajoutée pallie le problème précédent, mais ne permet pas d’obtenir un objet directement utilisable (équivalent à un tableau associatif), mais un tableau de tableaux:
nous avons donc crée une nouvelle action, arrays2objects, qui permet de modifier ce tableau (transformer les tableaux internes en objets) qui pourront ensuite être utilisés par l’action array2object pré-existante (que l’on utilisait déjà avec le fichier JSON externe).
Ce sprint n°13 a été consacré à la consolidation de l’outil ezVIS. Nous avons principalement modifié la documentation et corrigé des bugs.
Tâches
20 tâches prévues
18 tâches effectuées (dont 15 avaient été prévues)
24 tâches au total
plus de 24 points de complexité prévus
37,5 points de complexité effectués
Le nombre de points de complexité prévus était très peu précis, car nous avions plusieurs bugs. Les bugs sont par définition difficile à estimer. N’ont pas été comptabilisés ici les travaux de déclaration des bugs par les documentalistes/utilisateurs.
Production
Basculements des URL publics
Les URL publics des rapports du service Appui au Pilotage de l’Inist pointent maintenant sur la machine de production dont la mise au point a été finalisée (via puppet). Au passage, les instances ont été copiées de la machine d’intégration vers la machine de production (et vérifiées par les gestionnaires de ces instances).
Augmentation de l’espace disque
À cause de la manière dont ezVIS gère le cache des requêtes qu’il utilise, la place utilisée par une de ses instances dans la base de données augmente à mesure que ses utilisateurs en font des usages variés.
C’est pourquoi nous avons fait augmenter par le service Ingénierie de Production l’espace disque disponible sur la machine de production (c’était 10 Go au total sur la machine d’intégration, c’est 200 Go sur la machine de production).
Bugs
Déclaration des bugs par les gestionnaires
Ce sprint ayant été dédié à la consolidation d’ezVIS, nous avons demandé aux gestionnaires des instances déjà existantes de faire une déclaration formelle des bugs qu’ils ont rencontré. De plus, ils ont dû faire en faire qu’on puisse reproduire ces bugs. Nous avons donc utilisé l’application ezREF présente sur la machine d’intégration, et fait utiliser l’interface de dépôt de fichiers sur ce serveur pour y mettre:
la description du dysfonctionnement (dans un fichier *README.txt)
la configuration de l’instance (dans un fichier *.json)
le(s) corpus dans un ou plusieurs fichier(s) dont préfixe était commun à tous les fichiers concernant ce bug.
Tout le monde a parfaitement joué le jeu et nous avons obtenu la description de 5 bugs:
Dans plusieurs des bugs déclarés, lors du chargement des données au premier lancement, ezVIS ne rendait pas la main: la déclaration Files and Database are synchronised. n’arrivait pas (même quand tous les documents avaient été chargés), et donc encore moins le calcul des corpusFields (les métriques sur le corpus). Souvent d’ailleurs, on pouvait contourner ce problème en relançant simplement l’instance (ezVIS détectait alors que le(s) fichier(s) n’avaient pas changés, et passait directement à l’étape suivante: le calcul des métriques).
Il s’est avéré que ce cas arrivait quand une erreur survenait lors du chargement (soit un problème de parsing du fichier, soit un problème JBJ lors du calcul des documentFields). L’analyse a révélé que lors du chargement, les erreurs étaient complètement ignorées, et qu’ezVIS essayait quand même de traiter les données, sans même afficher l’erreur.
Dorénavant, l’erreur est affichée, accompagnée du nom du fichier et du numéro du document, dans ce fichier, pour lequel l’erreur s’est produite.
$ ezvis bibliotep_entier_pertes Core version : 2.5.0 Configuration : /home/parmentf/dev/castorjs/bugs/bibliotep_entier_pertes.json Theme : /home/parmentf/dev/castorjs/ezvis App : ezvis 6.7.3 Source : /home/parmentf/dev/castorjs/bugs/bibliotep_entier_pertes Server is listening on port 3000: http://localhost:3000 Index field : annee/annee_1 Index field : titre/titre_1 Index field : wid/wid_1 Index field : neoplasms/neoplasms_1 Index field : techniques/techniques_1 Index field : pays/pays_1 Index field : auteurs/auteurs_1 Index field : vpmid/vpmid_1 Index field : elements/elements_1 Index field : pmid/pmid_1 Index field : anatomical/anatomical_1 Index field : isotopes/isotopes_1 Index field : source/source_1 Index field : text/text_text error [TypeError: Cannot call method 'slice' of undefined] in file /home/parmentf/dev/castorjs/bugs/bibliotep_entier_pertes/bibliotep_entier_pertes_2014-2015.csv document # 3431 error [TypeError: Cannot call method 'slice' of undefined] in file /home/parmentf/dev/castorjs/bugs/bibliotep_entier_pertes/bibliotep_entier_pertes_2014-2015.csv document # 3643 error [TypeError: Cannot call method 'slice' of undefined] in file /home/parmentf/dev/castorjs/bugs/bibliotep_entier_pertes/bibliotep_entier_pertes_2014-2015.csv document # 3645 error [TypeError: Cannot call method 'slice' of undefined] in file /home/parmentf/dev/castorjs/bugs/bibliotep_entier_pertes/bibliotep_entier_pertes_2014-2015.csv document # 3738 error [TypeError: Cannot call method 'slice' of undefined] in file /home/parmentf/dev/castorjs/bugs/bibliotep_entier_pertes/bibliotep_entier_pertes_2014-2015.csv document # 3855 error [TypeError: Cannot call method 'slice' of undefined] in file /home/parmentf/dev/castorjs/bugs/bibliotep_entier_pertes/bibliotep_entier_pertes_2014-2015.csv document # 3895 Files and Database are synchronised. 127.0.0.1 - - [20/Jul/2015:15:41:03 +0000] "GET /compute.json?operator=count&field=wid HTTP/1.1"200 - "-""-" 127.0.0.1 - - [20/Jul/2015:15:41:03 +0000] "GET /compute.json?operator=distinct&field=annee HTTP/1.1"200 - "-""-" 127.0.0.1 - - [20/Jul/2015:15:41:03 +0000] "GET /compute.json?operator=distinct&field=isotopes HTTP/1.1"200 - "-""-" Corpus fields computed.
Cette correction a modifier le comportement d’ezVIS sur plusieurs des bugs déclarés, révélant alors que c’était plutôt les fichiers d’origine qui ne respectaient pas le format demandé (CVS et l’échappement des guillemets, par exemple).
Correction: mettre à jour l’instance quand la configuration est modifiée
Un comportement pratique d’ezVIS a cessé de fonctionner il y a déjà quelques sprints: quand on modifie la configuration d’une instance et qu’on la relance sans modifier les données, les documents ne prennent pas en compte les modifications de la configuration. En particulier, quand un gestionnaire modifie les documentFields, ces nouveaux champs ne sont calculés que pour les nouveaux documents (ou pour aucun). C’est très handicapant quand on met au point une configuration car on est alors contraint, quand on passe par ezMaster, de supprimer l’instance et de la recréer (ce qui implique de recharger les données).
Ce comportement a été rétabli: quand on modifie une configuration, si les documents sont plus anciens que le fichier de configuration, ezVIS les mets à jour en prenant en compte la nouvelle configuration.
Correction: mettre à jour l’instance quand les fichiers sont modifiés
Quand un fichier déjà chargé dans l’instance est remplacé par un fichier du même nom mais contenant des lignes en moins, les lignes ne disparaissaient pas.
Après une enquête approfondie (merci à Yannick pour son aide), nous avons trouvé et corrigé le bug.
ATTENTION : il est possible que des métriques faisant un comptage des documents ne soient pas mises à jour immédiatement. Dans ce cas, il est nécessaire de redémarrer l’instance (ou de la mettre en pause de la relancer, via ezMaster) pour bénéficier d’un calcul à jour.
Nouvelle documentation
Il commençait à être difficile de s’y retrouver dans l’ancienne documentation d’ezVIS, qui tenait sur une page, mais était dépourvue de table des matières (et souvent faisait référence à la documentation d’autres projets).
Il a donc été décidé d’utiliser un système dédié à la documentation de projets informatiques, qui se base sur le même format que l’ancienne documentation (Markdown): ReadTheDocs.
La nouvelle documentation, divisée en pages plus courtes, et agrémentée d’illustrations, est donc disponible sur http://ezvis.readthedocs.org/ ou http://ezvis.rtfd.org/. Elle est mise à jour à chaque mise à jour du dépôt GitHub, et responsive (lisible sur un téléphone mobile). Au besoin, on pourrait même en garder des versions différentes (une pour la version 6.*, et une pour la version suivante, par exemple).
Quand on a oublié MongoDB avant de lancer ezVIS, il y a maintenant un message d’erreur:
1
failed to connect to [localhost:27017]
Il est certes sibyllin, mais il est difficile de faire mieux (principalement en raison du fait qu’ezVIS n’établit la connexion à MongoDB que lorsqu’il en a besoin).
oubli du paramètre
ezVIS a un paramètre obligatoire: le chemin du répertoire où se trouvent les fichiers contenant les données. Auparavant, le message était très technique, et même les programmeurs avaient besoin de toute leur expérience pour le comprendre.
Maintenant c’est celui ci:
1 2 3 4 5
$ ezvis Usage: ezvis data data being a directory path, and data.json the settings file. See https://github.com/madec-project/ezvis for more details.
Afin de pouvoir afficher les erreurs JBJ (dues à la configuration des documentFields, corpusFields et flyingFields), nous avons mené une opération d’homogénéisation du traitement des erreurs dans JBJ. Il sont maintenant traités comme n’importe quelle erreur dans ezVIS (en particulier lors du chargement des données).
Quand getProperty et getPropertyVar sont appliqués à un tableau, il est plus naturel d’utiliser getIndex et getIndexVar (cliquez sur les liens pour voir des exemples dans la documentation de JBJ version ReadTheDocs).
Les exemples étaient initialement classés par sujet, et partageaient leur input. Nous avons supprimé le premier niveau (sujet). Nous en avons aussi profité pour supprimer un effet de bord gênant: quand une feuille de style modifiait l’input, elle le modifiait aussi pour les autres exemples du même sujet. Chaque exemple est maintenant indépendant.
Pour en profiter: npm install -g castor-clean. (version 1.2.0).
ezref: usage
Comme pour ezVIS, quand on oublie le paramètre obligatoire d’ezref, on a maintenant un message indiquant l’usage normal de la commande:
1 2 3 4 5
$ ezref Usage: ezref public public being a directory path, and public.json the settings file. See https://github.com/madec-project/ezref for more details.
ezvis: mise à jour de dépendances
Il existe un site qui recense la fraîcheur des dépendences de projets Node, et qui signale des trous de sécurité potentiels.
J’ai donc procédé à quelques mises à jour (marked, sha1, et qs).
Sans doute à surveiller de près.
Comme d’habitude, pour profiter des ajouts de ce sprint dans ezVIS :