Nous voici arrivés à la sprint review n°12, qui concerne les calculs complexes.
Comme le dit Anne-Marie, la division est une opération complexe par rapport au simple comptage. Mais la complexité dont nous parlons réside plutôt dans l’appel des données intégrées aux calculs: ils sont externes, dans des tableaux.
Tâches
- 10 tâches prévues
- 10 tâches effectuées (dont 9 avaient été prévues)
- 24 tâches au total
- plus de 25 points de complexité prévus
- 24,5 points de complexité effectués
Ce ne sont là que les points pour le développement, sachant que les utilisateurs ont fait plus (notamment sur les tests).
Calcul d’un taux de citation normalisé
Nous avons identifié 4 étapes pour le calcul d’un taux de citation normalisé:
- calculer le nombre de publications par année
- calculer le nombre de citations par année
- calculer le taux de citations par année
- normaliser ce taux par rapport à un taux de citation global
1. Calculer le nombre de publications par année
Ce calcul se fait sur le corpus complet, donc on peut stocker le résultat dans un corpusFields (appelons-le publiPerYear).
Nous avons un opérateur classique pour compter le nombre de documents par valeurs distinctes d’un champ: distinct.
1 | { |
Nous obtenons donc:
1 | [ |
2. Calculer le nombre de citations par année
De la même manière, ce calcul peut se faire sur tout le corpus. On le stocke dans le corpusFields nommé citationsPerYear:
1 | { |
Cette fois, nous avons utilisé l’opérateur sum_field1_by_field2 qui ramène bien ce qui nous intéresse:
1 | [ |
3. calculer le taux de citations par année
Calculer le taux de citations par année revient à diviser la valeur de citationsPerYear par celle qui correspond dans publiPerYear (donc, le nombre de citations pour une année par le nombre de publications pour cette année, ce qui donne bien le nombre moyen de citations par publication, ou taux de citation):
1 | "$citationRatioPerYear": { |
Ici, nous obtenons un résultat sous forme d’un tableau d’éléments structurés { _id, value } qui sont nécessaires pour pouvoir dessiner un graphe.
4. normaliser ce taux par rapport à un taux de citation global
Une fois qu’on a le taux de citations par années, on peut le diviser par le taux de citations global par années (obtenu par un autre moyen).
Pour cela, on va stocker dans un serveur web statique (par exemple un ezref) un fichier JSON contenant cette table:
1 | [{"_id":2004,"value":23.56},{"_id":2005,"value":21.87},{"_id":2006,"value":19.83},{"_id":2007,"value":17.9},{"_id":2008,"value":15.56},{"_id":2009,"value":13.38},{"_id":2010,"value":10.9},{"_id":2011,"value":8.11},{"_id":2012,"value":5.37},{"_id":2013,"value":2.61},{"_id":2014,"value":0.53}] |
Puis, nous ajoutons un corpusFields nommé globalCitationRatios:
1 | { |
Pour obtenir un objet JSON:
1 | { |
JBJ: getPropertyVar et array2object
Cet objet JSON donne directement accès à un taux de citation global, en utilisant, par exemple "getproperty": "2008", on récupère la valeur associée: 15.56.
C’est pourquoi nous avons créé l’action array2object, qui transforme un tableau d’objets {_id,value} en objet associant les _id et les values.
Malheureusement, l’action JBJ getproperty ne prend qu’un paramètre littéral, et s’applique sur l’environnement courant. Or, nous voulons parcourir le tableau des taux de citations pour pouvoir normaliser chaque valeur par rapport à la valeur correspondante dans le tableau global.
Nous avons donc créé le pendant de getproperty prenant des variables en paramètres: getpropertyvar, qui prend en paramètre un tableau de deux noms de variables: la variable contenant le tableau, et la variable contenant l’indice à aller chercher.
Ça a permis d’appliquer le flyingFields suivant au résultat de l’opérateur retournant le nombre de publication par année:
1 | "$normalizeCitationRatioPerYear": { |
Rappel : flyingFields a accès à la fois aux corpusFields et aux variables _id et value retournées par l’opérateur (distinct dans ce cas), citationsPerYear et globalCitationRatios étant des corpusFields, ils sont accessibles aussi.
Ce flyingFields appliqué à l’opérateur distinct(Year) via l’URL http://localhost:3000/compute.json?o=distinct&f=Year&ff=normalizeCitationRatioPerYear renvoie un data dont le contenu est prêt à être affiché dans un chart (soit un histogram, soit un horizontalbars, soit un pie):
1 | [ |
Graphes superposés
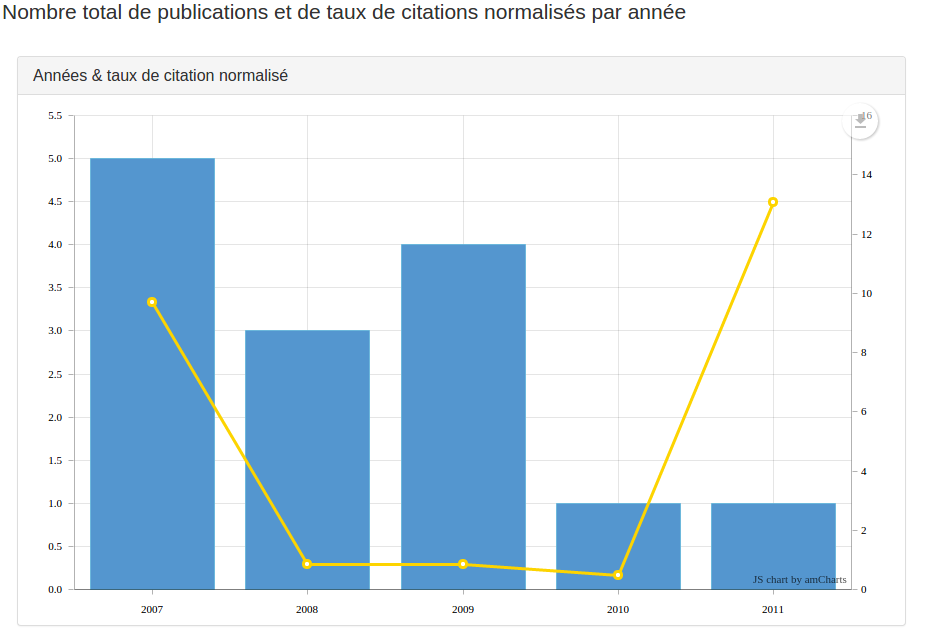
Un taux de citation normalisé par année est intéressant à comparer à un nombre de publications par année, sur un corpus donné. Dans les versions 6.6 d’ezVIS, le seul moyen disponible était de créer un graphe avec les publications par année, puis un autre graphe avec les taux de citations pour qu’ils soient un au-dessus de l’autre dans le tableau de bord. Pas très pratique.
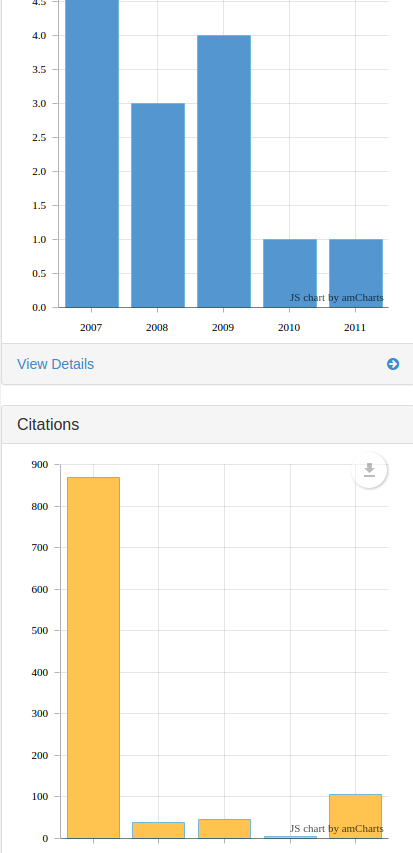
Un autre moyen est de superposer les deux graphiques (une manière classique est d’avoir un histogramme et une ligne, comme dans cette démonstration de la bibliothèque amCharts).
Nous avons donc introduit le moyen de le faire avec ezVIS 6.7.2, en ajoutant la propriété overlay à un graphique de type histogram:
1 | { |
Un overlay doit contenir un label (qui s’affiche sur les points de la ligne), et un flying qui s’appliquera sur les data fournis par l’opérateur (par défaut distinct) et les fields.
La convention est un qu’un overlay se nourrit d’éléments semblables à ceux d’un chart normal (composé d’un _id et d’une value) auquels on ajoute une deuxième valeur value2.
Il faut donc modifier le flyingFields nommé normalizeCitationRatioPerYear exposé plus haut:
1 | { |
firstOnly
Quand on veut appliquer le même genre de flyingFields à des valeurs déjà présentes dans corpusFields, on est quand même obligé de passer par une route de type compute qui applique un opérateur retournant systématiquement un tableau de résultats (même quand il n’y en a qu’un).
Or le principe des flyingFields est de s’appliquer à tous les éléments de ce tableau data. On obtient donc un tableau de tableaux, qu’ezVIS n’est pas capable d’interpréter. Nous avons donc ajouté la propriété firstOnly qui, au lieu de renvoyer un tableau d’éléments, ne renvoie que le premier élément du tableau. Voir le ticket Add a “firstOnly” parameter to the routes returning data.
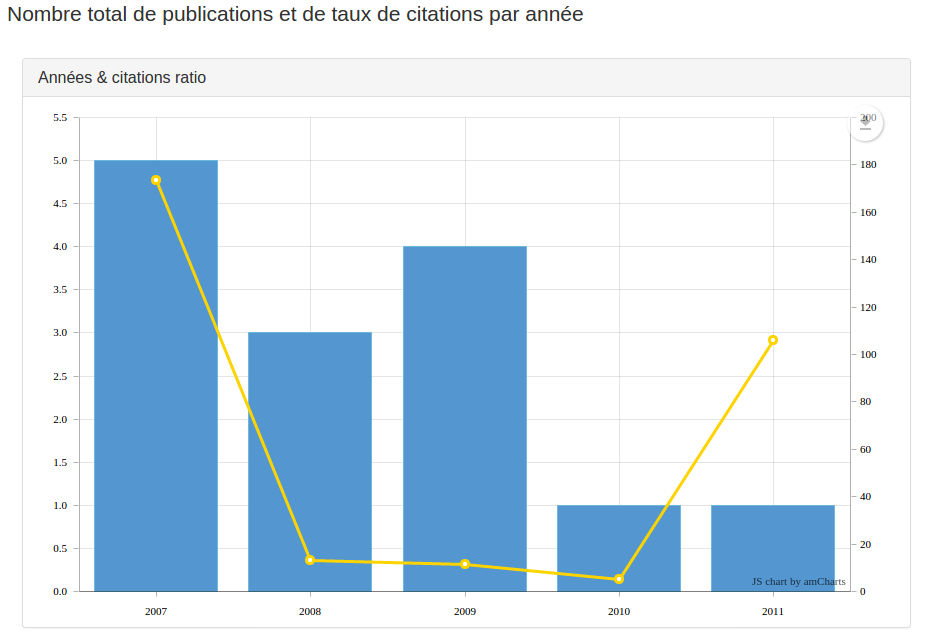
Ainsi, quand on veut afficher un histogram avec un overlay contenant les taux de citations par années (présents dans le corpusFields appelé citationsPerYear), il faut utiliser une configuration comme celle-là (contenant un firstOnly):
1 | { |
sans oublier de modifier le flyingFields nommé publiCitationRatioPerYear pour qu’il renvoie deux valeurs:
1 | { |
Tests de chargement (.tsv WoS)
Nous utilisons des fichiers extraits du WoS (Web of Science) au format TSV (Tabulation Separated Values), et certaines notices passaient mal.
Nous avons trouvé des champs contenant des guillemets (double quotes anglaises), non échappés (mais c’est normal, il n’y avait pas d’ambiguité), et c’est visiblement ce qui posait problème. Une correction a été apportée à la bibliothèque qui analyse les CSV: csv-string. Voir ticket 19 de csv-string.
Mais après tests, les fichiers qui posaient problème ne passent toujours pas correctement: sur un corpus de 999 notices, seules les notices contenant des guillemets ne sont pas chargées (en enlevant les guillemets, tout passe).
Tests de dépôt de plusieurs fichiers (XML ou CSV)
Nous avons remarqué un comportement erronné d’ezVIS: quand on met deux fichiers XML dans le répertoire des données, on obtient des erreurs SAX, alors que séparément, les deux fichiers sont bien chargés.
Après test, ce comportement ne se produit pas avec des fichiers CSV.
Test de la machine de production avec plus de dix rapports
13 rapports ont été créés sur la machine de production, sans aucun problème (rappel: 12 rapports étaient déjà de trop sur la machine d’intégration avant qu’ezMaster soit corrigé).
Test de la prise en compte des modifications de configuration dans ezMaster
Les modifications des documentFields dans la configuration d’une instance ne sont pas prises en compte, même après rechargement du corpus.
Test de la prise en compte des modifications de corpus dans ezMaster
Les modifications du corpus d’une instance (suppression de notices) ne sont pas prises en compte.
Par contre l’ajout d’un nouveau corpus dans la même instance est bien traité et les modifications des documentFields dans la configuration d’une instance sont également prises en compte pour le nouveau corpus.
Documentation du protocole HTTP dans les documentFields
L’utilisation du protocole HTTP dans les documentFields n’avait pas été documentée, c’est chose faite: 6a7147.
Modification des entêtes des exports
Les exports de documents prennent maintenant comme noms de colonnes les labels des champs, et non plus leurs identifiants. Voir ticket 48.
Mise à jour de getting-started-with-visir
Le dépôt getting-started-with-visir a été renommé en getting-started-with-ezvis, la documentation adaptée à la version 6+ d’ezVIS, ainsi que l’exemple fourni.
Explication d’ezVIS pour ISTEX
Kibana ne fournissant pas assez de graphiques, ISTEX s’est intéressé à ezVIS.
C’est l’occasion pour nous d’expérimenter le loader de corpus JSON castor-load-jsoncorpus.
Mise à jour / installation d’ezVIS
Pour profiter de la dernière version d’ezVIS:
1 | $ npm install --production -g ezvis |
À ce jour, c’est la version 6.7.2.